HPC Blog, 2021 Blog, AWS Service, Blog, Featured
AWS provides a comprehensive, elastic, and scalable cloud infrastructure to run your HPC applications. Working with AWS in exploring HPC for driving Scientific Research, Relevance Lab leveraged their RLCatalyst Research Gateway product to provision an HPC Cluster using AWS Service Catalog with simple steps to launch a new environment for research. This blog captures the steps used to launch a simple HPC 1.0 cluster on AWS and roadmap to extend the functionality to cover more advanced use cases of HPC Parallel Cluster.
AWS delivers an integrated suite of services that provides everything needed to build and manage HPC clusters in the cloud. These clusters are deployed over various industry verticals to run the most compute-intensive workloads. AWS has a wide range of HPC applications spanning from traditional applications such as genomics, computational chemistry, financial risk modeling, computer-aided engineering, weather prediction, and seismic imaging to new applications such as machine learning, deep learning, and autonomous driving. In the US alone, multiple organizations across different specializations are choosing cloud to collaborate for scientific research.

Similar programs exist across different geographies and institutions across EU, Asia, and country-specific programs for Public Sector programs. Our focus is to work with AWS and regional scientific institutions in bringing the power of Supercomputers for day-to-day researchers in a cost-effective manner with proper governance and tracking. Also, with Self-Service models, the shift needs to happen from worrying about computation to focus on Data, workflows, and analytics that requires a new paradigm of considering prospects of serverless scientific computing that we cover in later sections.
Relevance Lab RLCatalyst Research Gateway provides a Self-Service Cloud portal to provision AWS products with a 1-Click model based on AWS Service Catalog. While dealing with more complex AWS Products like HPC there is a need to have a multi-step provisioning model and post provisioning actions that are not always possible using standard AWS APIs. In these situations requiring complex orchestration and post provisioning automation RLCatalyst BOTs provide a flexible and scalable solution to complement based Research Gateway features.
Building blocks of HPC on AWS
AWS offers various services that make it easy to set up an HPC setup.
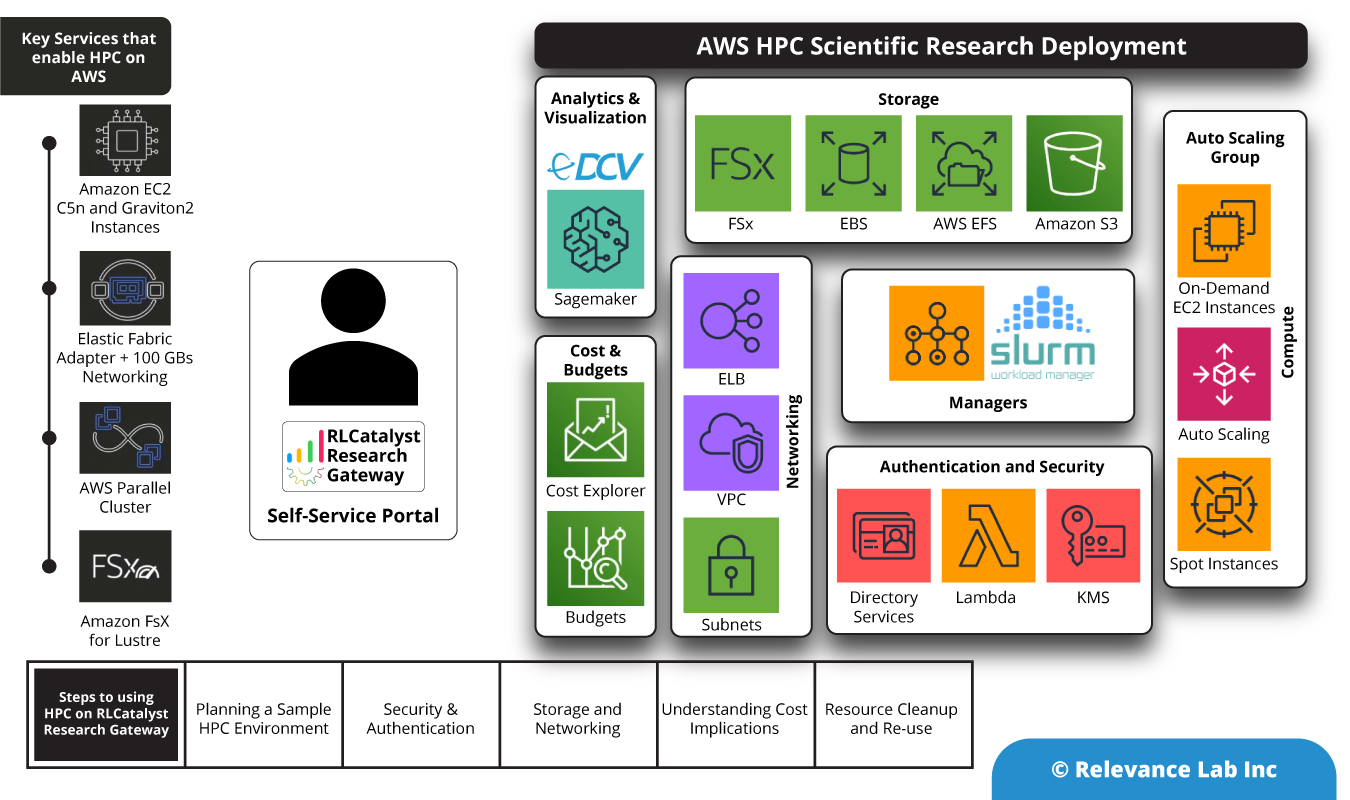
An HPC solution in AWS uses the following components as building blocks.
- EC2 instances are used for Master and Worker nodes. The master nodes can use On-Demand instances and the worker nodes can use a combination of On-Demand and Spot Instances.
- The software for the manager nodes is built as an AMI and used for the creation of Master nodes.
- The agent software for the managers to communicate with the worker nodes is built into a second AMI that is then used for provisioning the Worker nodes.
- Data is shared between different nodes using a file-sharing mechanism like FSx Lustre.
- Long-term storage uses AWS S3.
- Scaling of nodes is done via Auto-scaling.
- KMS for encrypting and decrypting the keys.
- Directory services to create the domain name for using HPC via UI.
- Lambda function service to create user directory.
- Elastic Load Balancing is used to distribute incoming application traffic across multiple targets, such as Amazon EC2 instances, containers, IP addresses, Lambda functions, and virtual appliances.
- Amazon EFS is used for regional service storing data within and across multiple Availability Zones (AZs) for high availability and durability. Amazon EC2 instances can access your file system across AZs.
- AWS VPC to launch the EC2 instances in private cloud.
Evolution of HPC on AWS
- HPC clusters first came into existence in AWS using the CfnCluster Cloud Formation template. It creates a number of Manager and Worker nodes in the cluster based on the input parameters. This product can be made available through AWS Service Catalog and is an item that can be provisioned from the RLCatalyst Research Gateway. The cluster manager software like Slurm, Torque, or SGE is pre-installed on the manager nodes and the agent software is pre-installed on the worker nodes. Also pre-installed is software that can provide a UI (like Nice EngineFrame) for the user to submit jobs to the cluster manager.
- AWS Parallel Cluster is a newer offering from AWS for provisioning an HPC cluster. This service provides an open-source, CLI-based option for setting up a cluster. It sets up the manager and worker nodes and also installs controlling software that can watch the job queues and trigger scaling requests on the AWS side so that the overall cluster can grow or shrink based on the size of the queue of jobs.
Steps to Launch HPC from RLCatalyst Research Gateway
A standard HPC launch involves the following steps.
- Provide the input parameters for the cluster. This will include
- The compute instance size for the master node (vCPUs, RAM, Disk)
- The compute instance size for the worker nodes (vCPUs, RAM, Disk)
- The minimum and maximum number of worker nodes.
- Select the workload manager software (Slurm, Torque, SGE)
- Connectivity options (SSH keys etc.)
- Launch the product.
- Once the product is in Active state, connect to the URL in the Output parameters on the Product Details page. This connects you to the UI from where you can submit jobs to the cluster.
- You can SSH into the master nodes using the key pair selected in the Input form.
RLCatalyst Research Gateway uses the CfnCluster method to create an HPC cluster. This allows the HPC cluster to be created just like any other products in our Research Gateway catalog items. Though this provisioning may take upto 45 minutes to complete, it creates an URL in the outputs which we can use to submit the jobs through the URL.
Advanced Use Cases for HPC
- Computational Fluid Dynamics
- Risk Management & Portfolio Optimization
- Autonomous Vehicles – Driving Simulation
- Research and Technical Computing on AWS
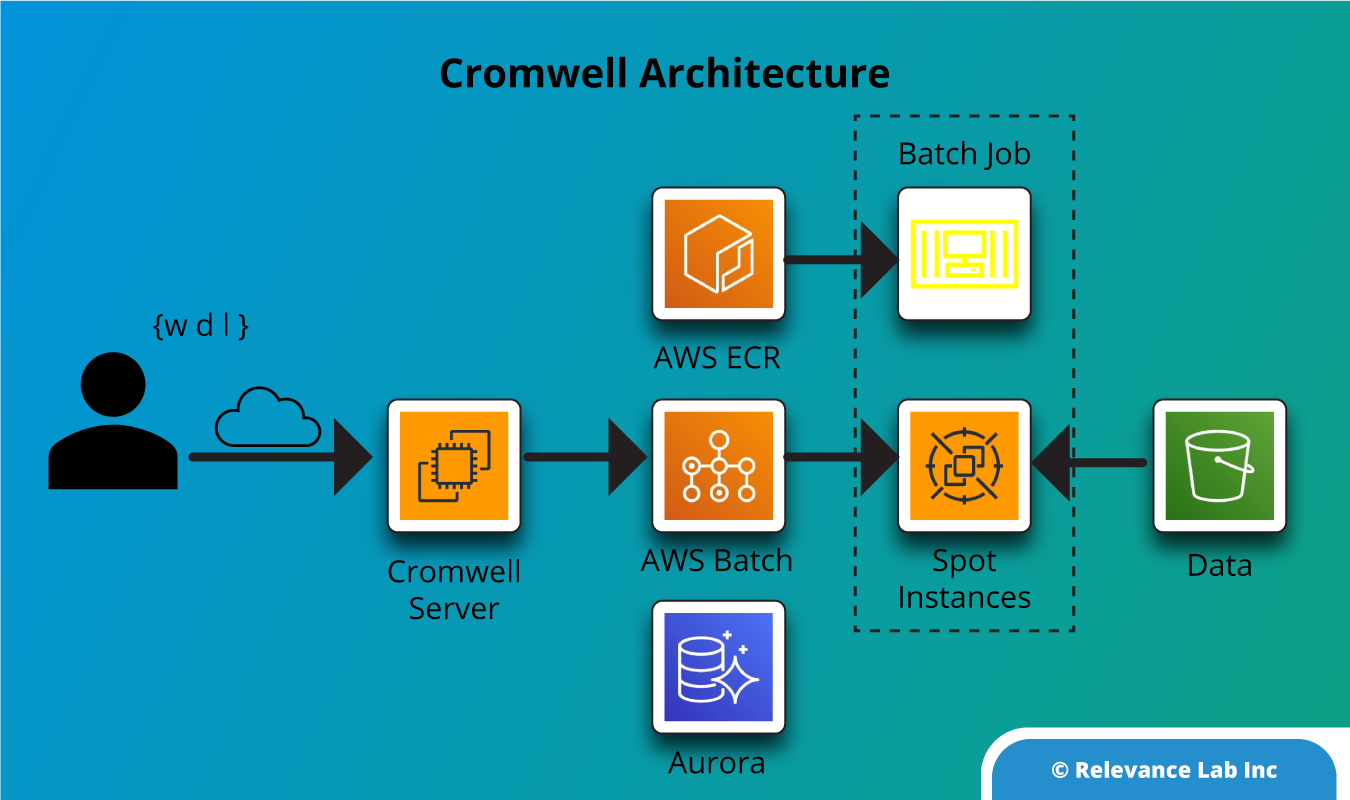
- Cromwell on AWS
- Genomics on AWS
We have specifically looked at the use case that pertains to BioInformatics where a lot of the research uses Cromwell server to process workflows defined using the WDL language. The Cromwell server acts as a manager that controls the worker nodes, which execute the tasks in the workflow. A typical Cromwell setup in AWS can use AWS Batch as the backend to scale the cluster up and down and execute containerized tasks on EC2 instances (on-demand or spot).
Prospect of Serverless Scientific Computing and HPC
“Function As A Service” Paradigm for HPC and Workflows for Scientific Research with the advent of serverless computing and its availability on all major computing platforms, it is now possible to take the computing that would be done on a High Performance Cluster and run it as lambda functions. The obvious advantage to this model is that this virtual cluster is highly elastic, and charged only for the exact execution time of each lambda function executed.
One of the limitations of this model currently is that only a few run-times are currently supported like Node.js and Python while a lot of the scientific computing code might be using additional run-times like C, C++, Java etc. However, this is fast changing and cloud providers are introducing new run-times like Go and Rust.
Summary
Scientific computing can take advantage of cloud computing to speed up research, scale-up computing needs almost instantaneously and do all this with much better cost efficiency. Researchers no longer worry about the expertise required to set up the infrastructure in AWS as they can leave this to tools like RLCatalyst Research Gateway, thus compressing the time it takes to complete their research computing tasks.
To learn more about this solution or participate in using the same for your internal needs feel free to contact marketing@relevancelab.com
References
Getting started with HPC on AWS
HPC on AWS Whitepaper
AWS HPC Workshops
Genomics in the Cloud
Serverless Supercomputing: High Performance Function as a Service for Science
FaaSter, Better, Cheaper: The Prospect of Serverless Scientific Computing and HPC