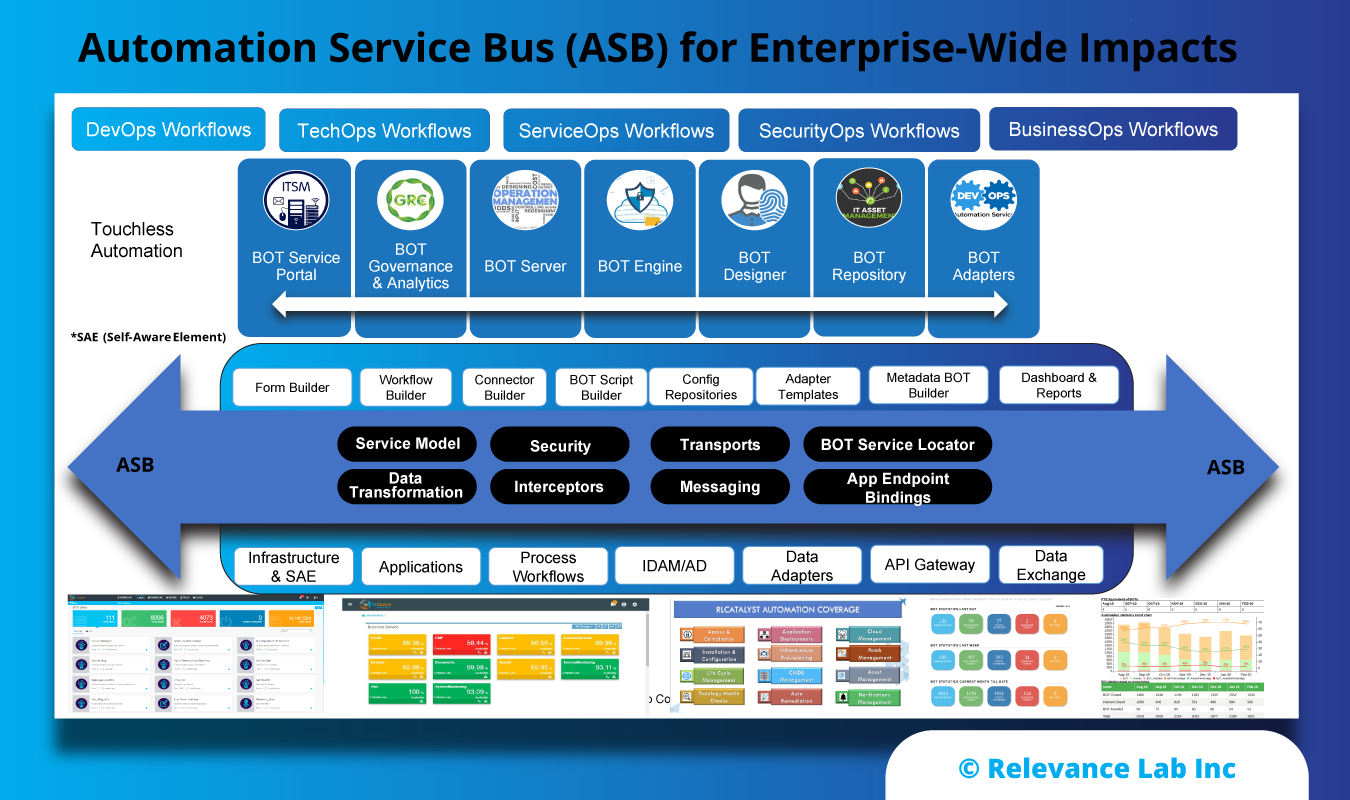
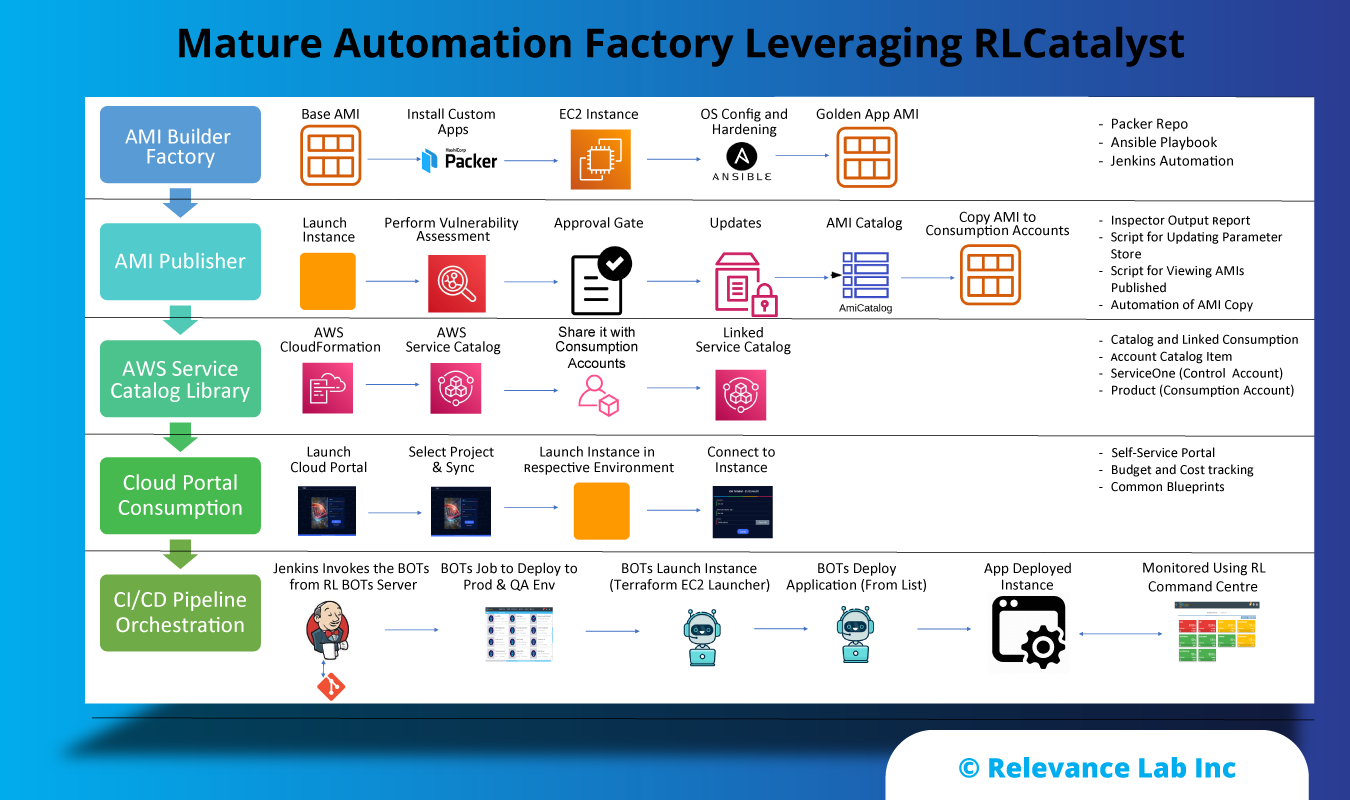
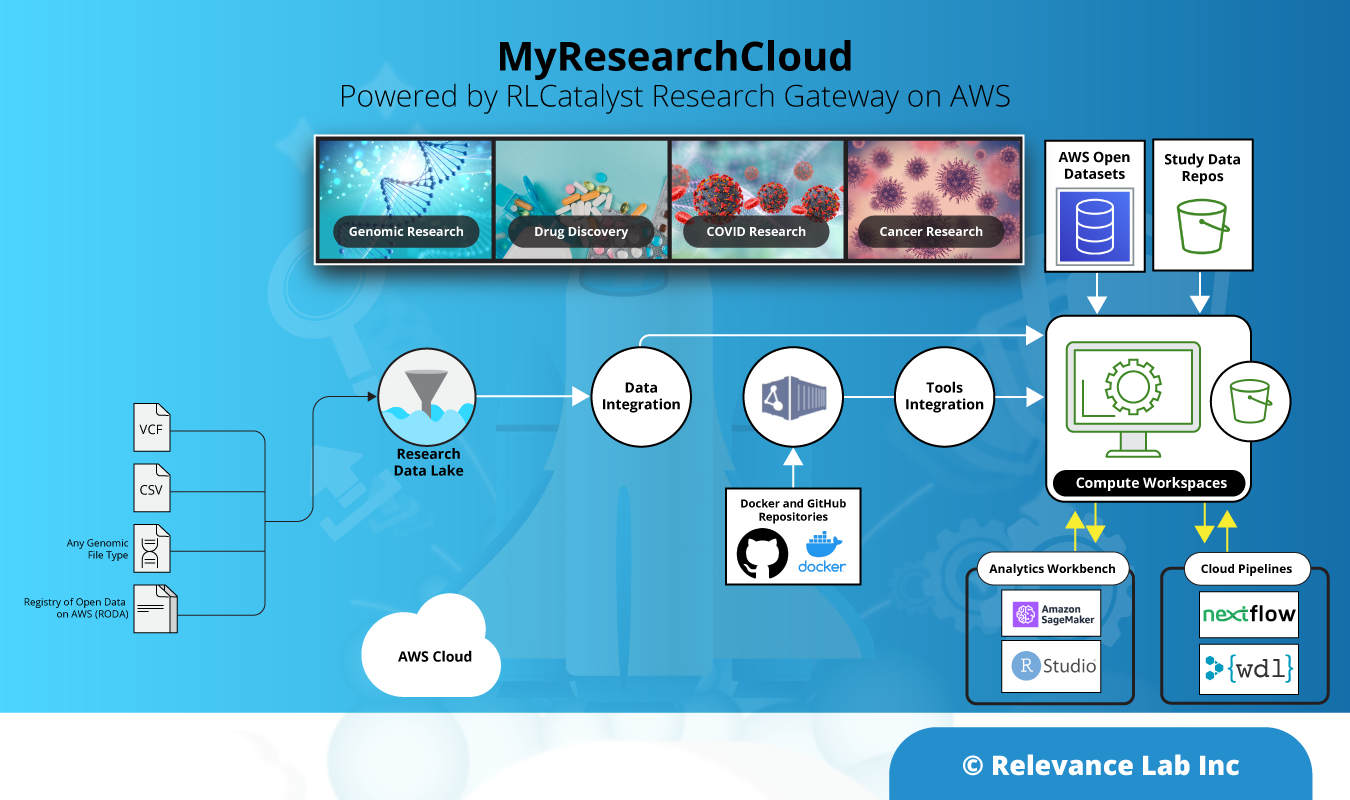
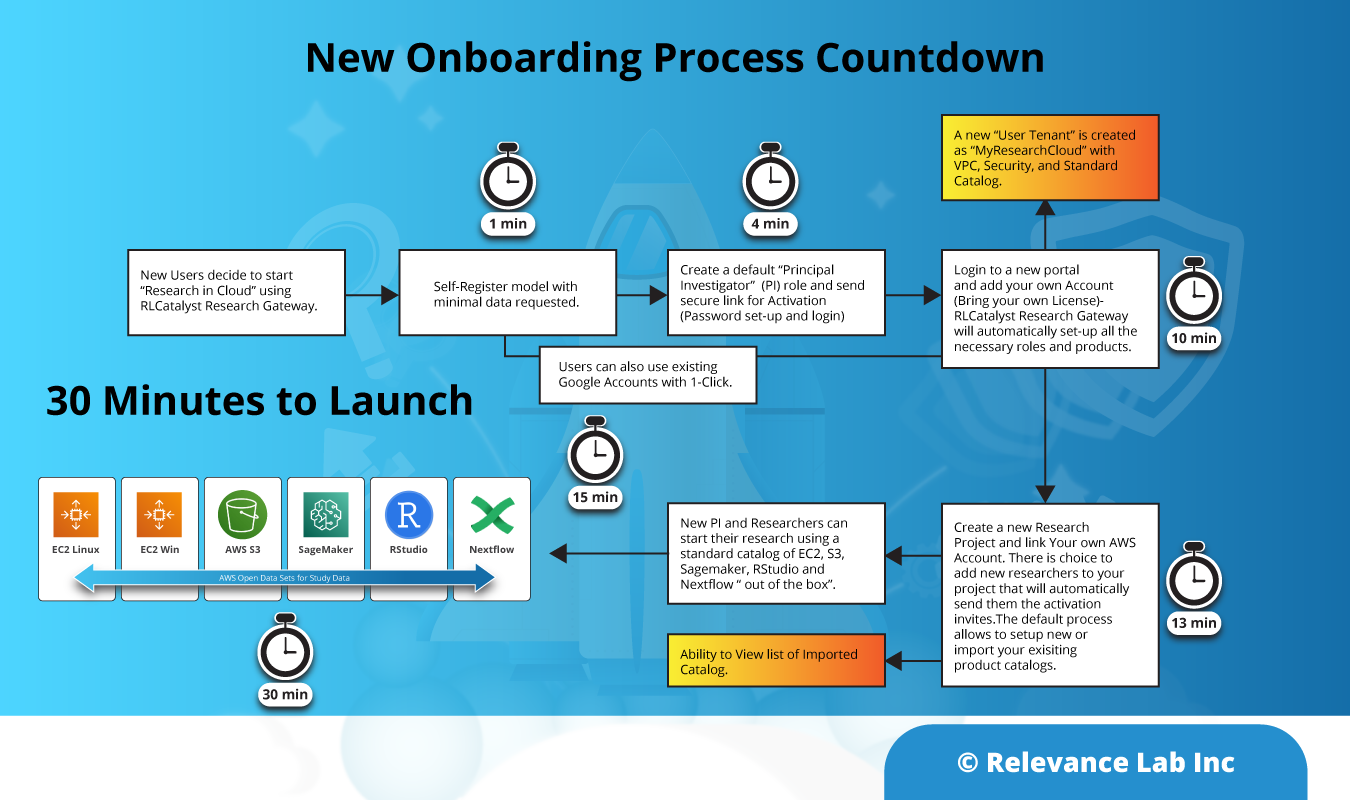
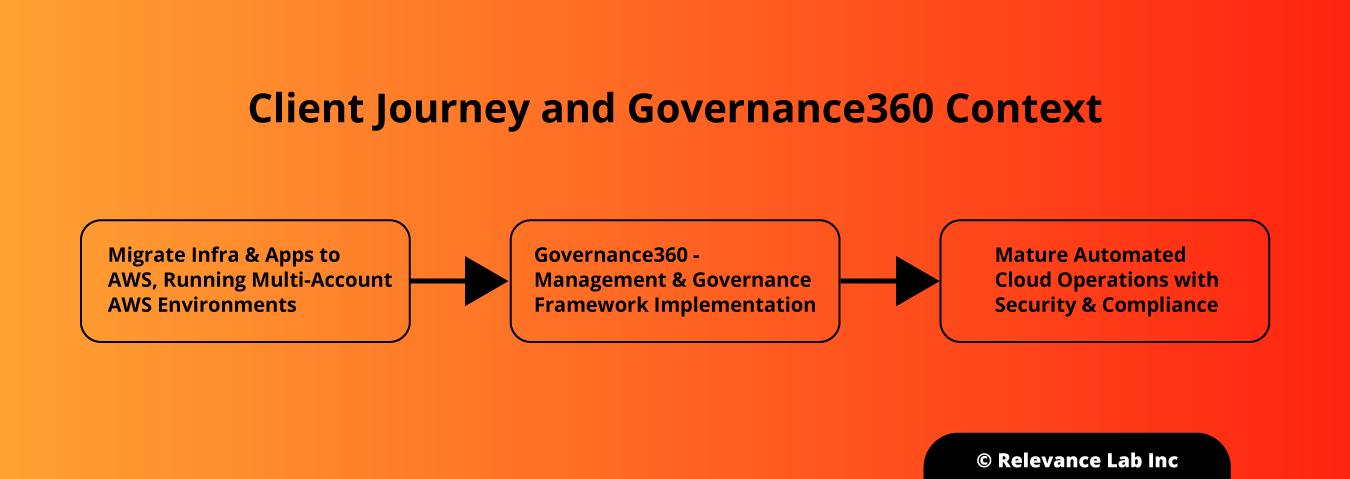
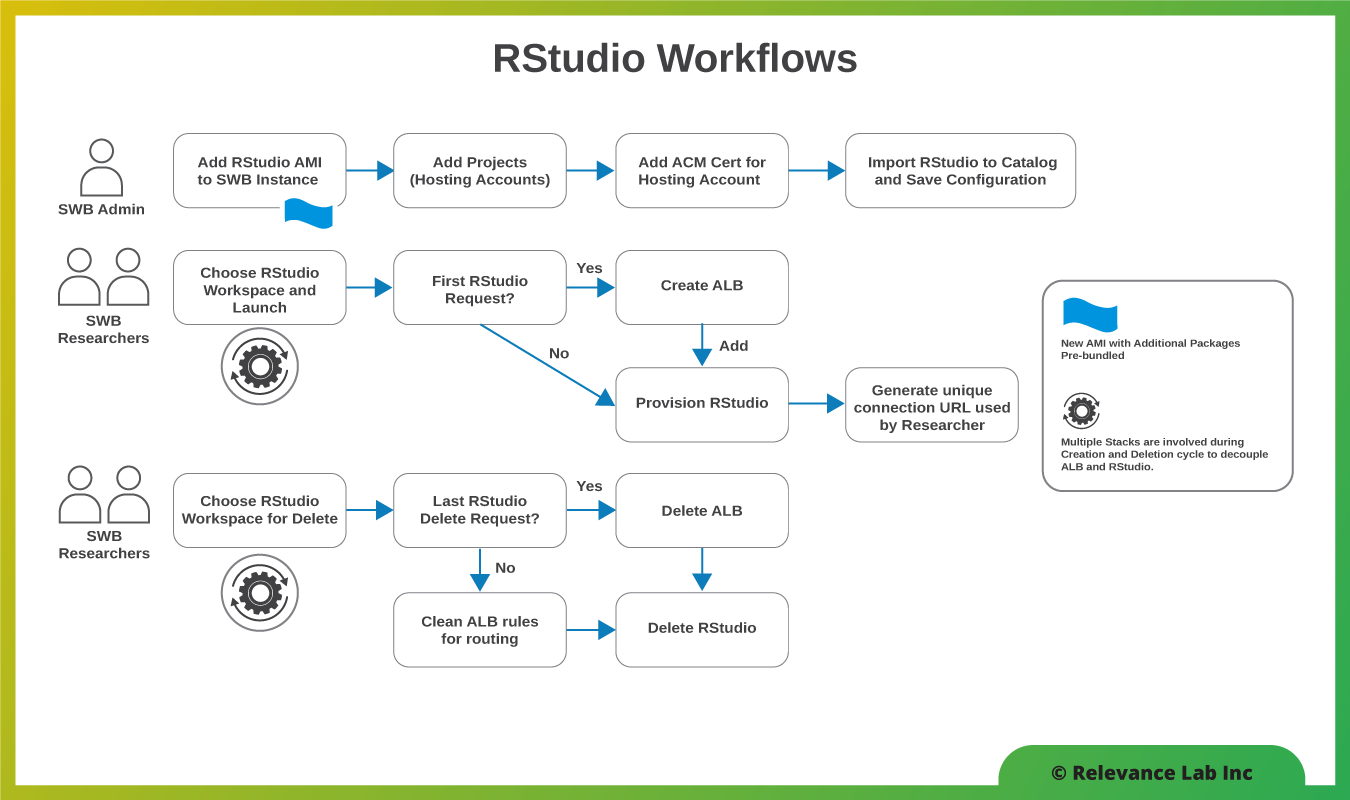
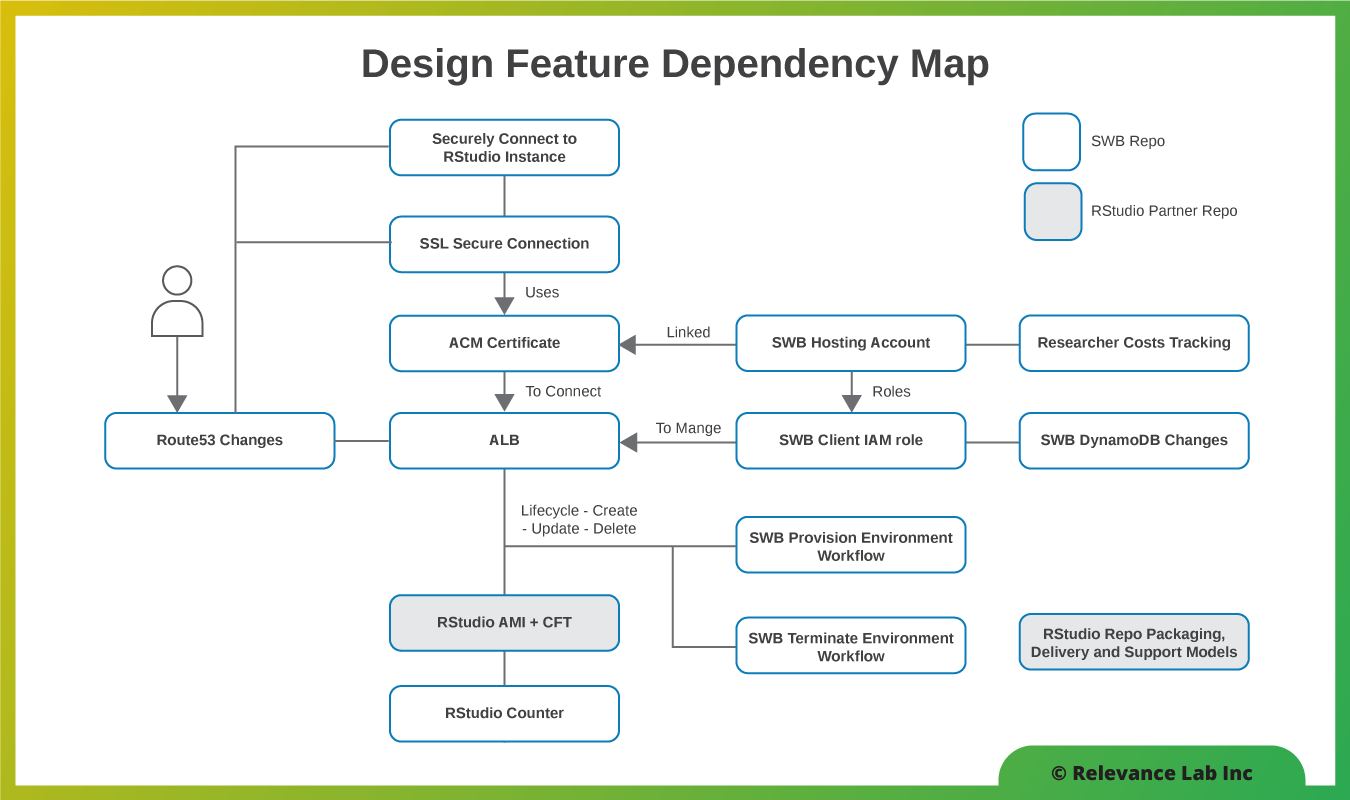
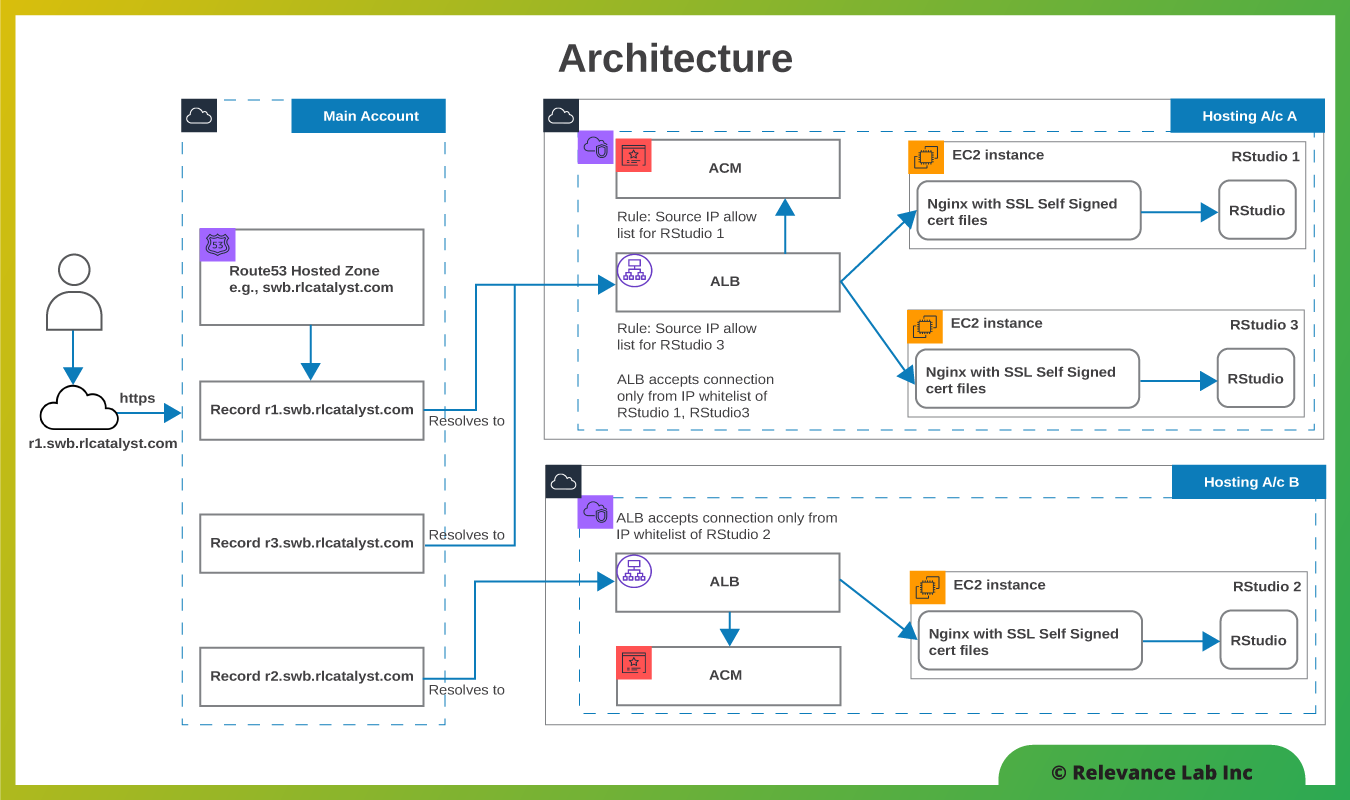
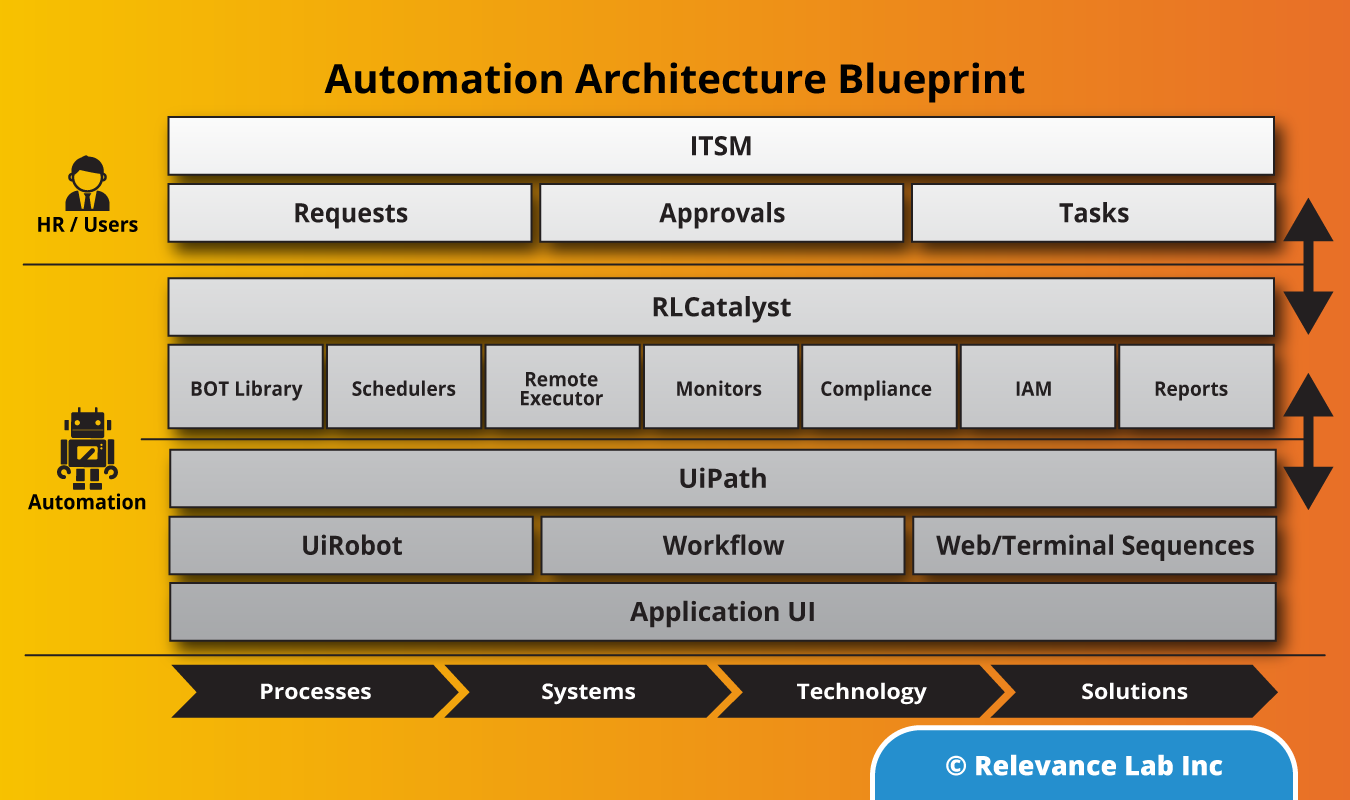
2021 Blog, Blog, Featured
The CMS-1500 form is vital to the smooth functioning of the American health insurance system, and yet processing these manually filled-up, paper-based forms can be a nightmare. Relevance Lab has developed a new approach to automating claims processing that improves output quality and delivers cost savings.
CMS-1500 Processing Challenges
The CMS-1500 form, formerly known as the HCFA-1500 form, is the standard claim form used by a non-institutional provider or supplier to bill Medicare carriers under certain circumstances. Processing these important documents presents several challenges:
- Large volume of information: A single form has 33 fields (plus sub-fields) to be filled up manually; multi-page claims are required if more than 6 services are provided.
- Illegible handwriting: Since the forms are filled manually (and often in a hurry), it is quite common to find illegible or difficult to read entries.
- Incomplete or inconsistent information: Fields are often missing or inconsistent (e.g. multiple spellings of the same name), complicating the task.
- Poor scan quality: The scan quality can be poor due to misorientation of the form, folds, etc., making it difficult to recognize text.
Most users are faced with a Hobson’s choice between costly manual processing and low-accuracy conventional automation solutions, neither of which produce acceptable results. Manual processing can be slow, laborious, fatigue-prone and costs tend to grow linearly with claims volumes, regardless of whether the manpower is in-house or outsourced. Conventional automation solutions based on simple scanning and optical character recognition (OCR) techniques struggle to deal with such non-standardized data leading to high error rates.
Relevance Lab has developed a solution to address these issues and make CMS-1500 claims processing simpler and more cost-efficient without compromising on accuracy.
Relevance Lab’s Smart Automation Solution
Our solution enhances the effectiveness of automation by utilizing artificial intelligence and machine learning techniques. At the same time, the workflow design ensures that the final sign-off on form validation is provided by a human.
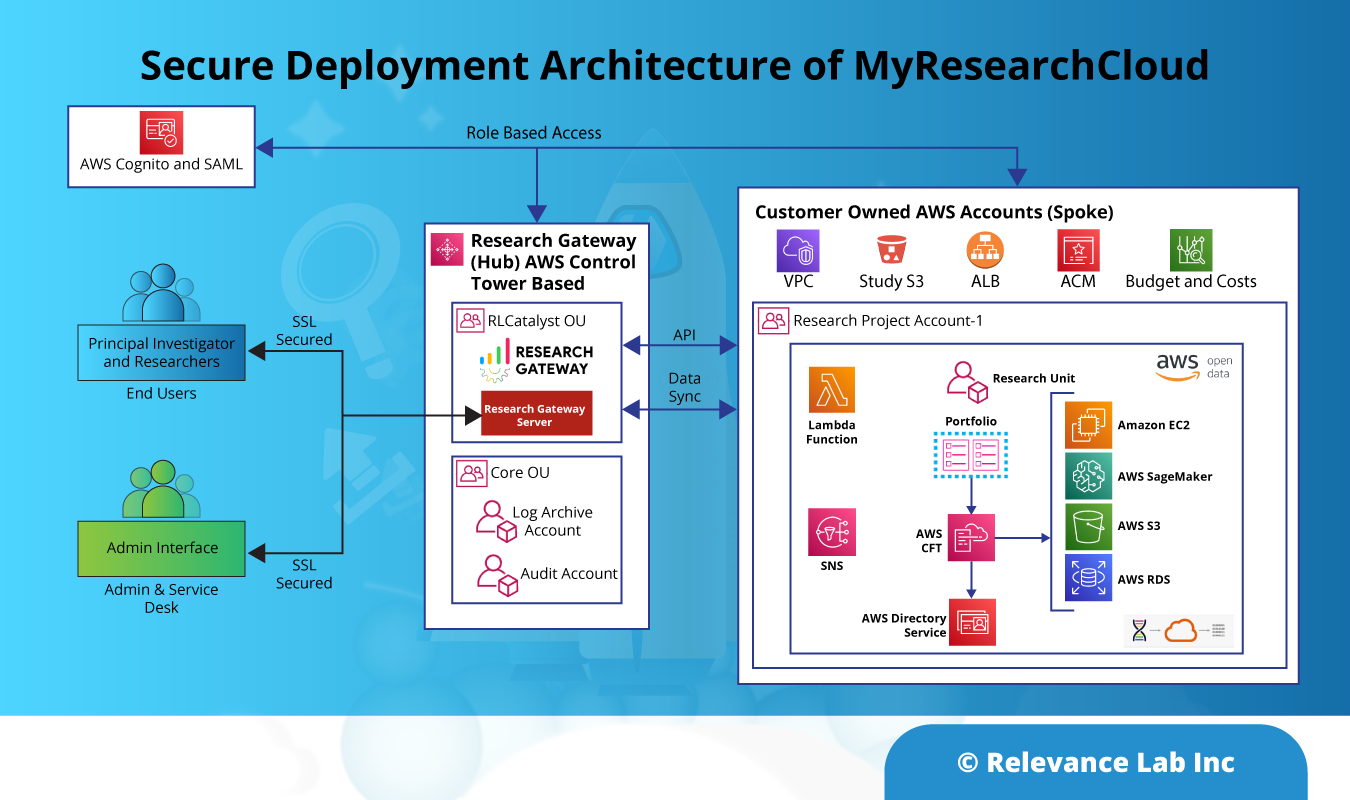
An illustrative solution architecture is given below:
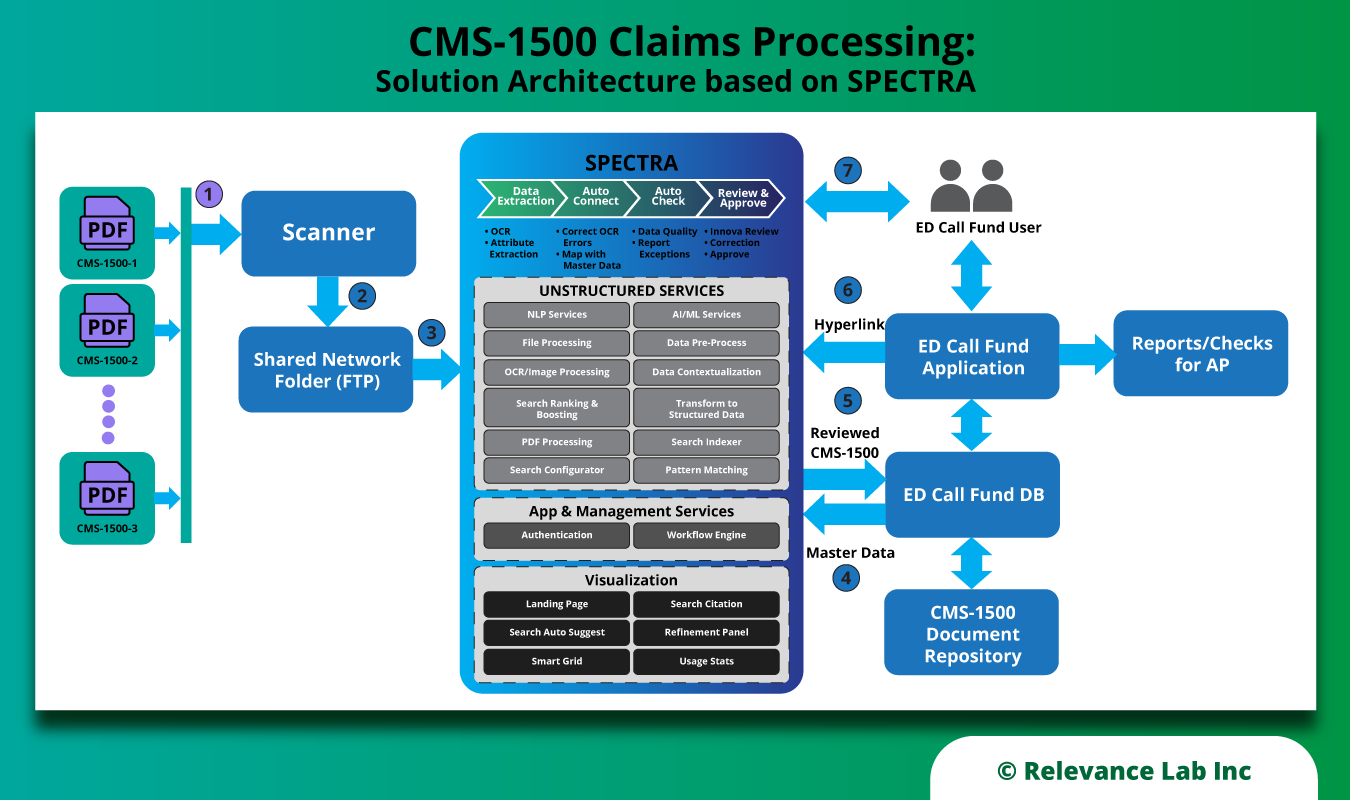
Salient features of the solution are as follows:
| Best-in-class OCR | The solution utilizes the Tesseract open-source OCR engine (supported by Google), which delivers a high degree of character recognition accuracy, to convert the scanned document into a searchable pdf. |
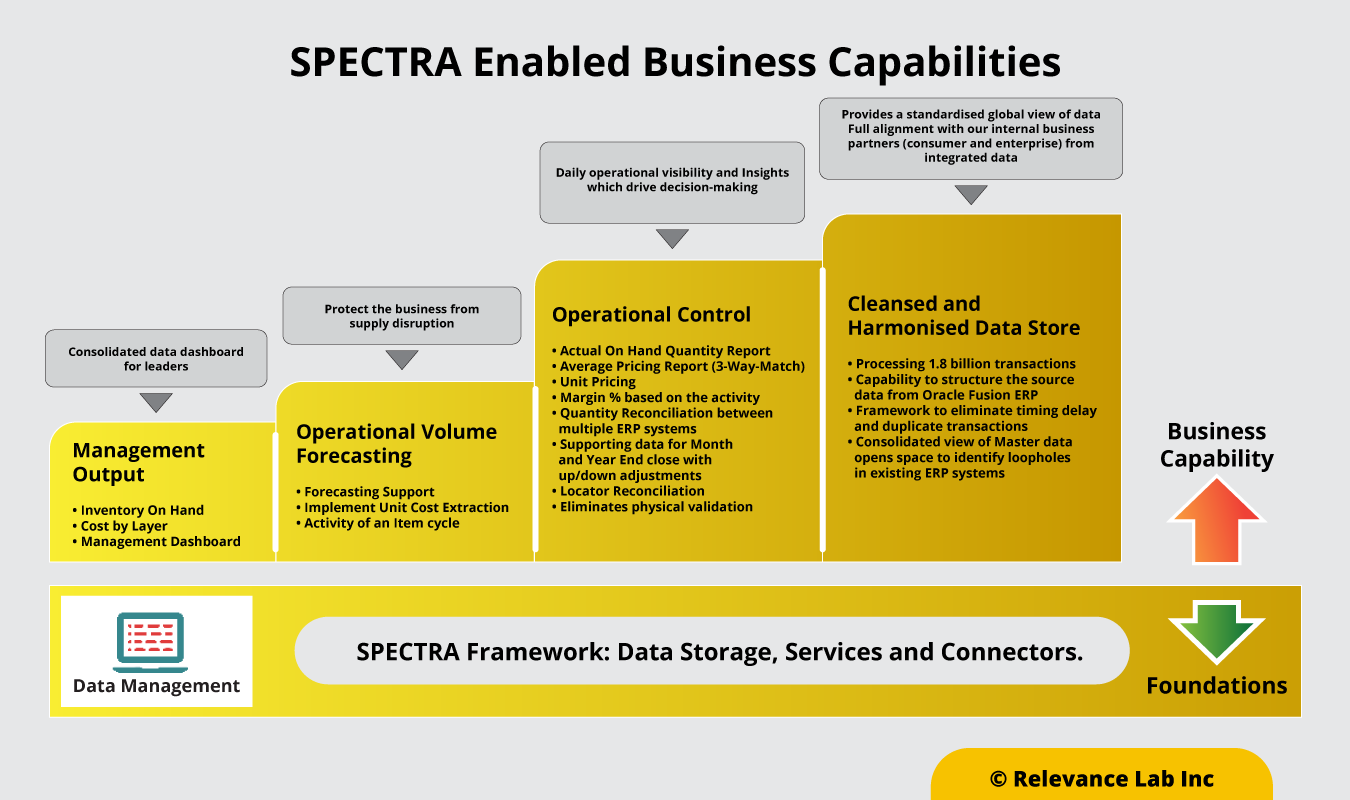
| Processing & Validation against master data | The document is analyzed using RL’s proprietary SPECTRA platform. Common errors (such as misaligned check-box entries) are corrected, and relevant fields are validated against the master data to catch anomalies (e.g. spelling errors). |
| Assisted human review | The updated document is presented for human review. Fields that require attention are highlighted, together with algorithm-generated guesstimates suggesting possible corrections. |
| Automatic update of downstream data | Once approved, downstream systems are automatically updated with validated data. |
| Self-learning | The iterative self-learning algorithm improves with every validation cycle resulting in continuous refinement in accuracy. This improvement can be tracked over time through built-in trackers. |
| Workflow tracking | The solution is equipped with dashboards that enable tracking the progress of a document through the cycle. |
| Role-based access | It is possible to enable role-based access to different modules of the system to ensure data governance. |
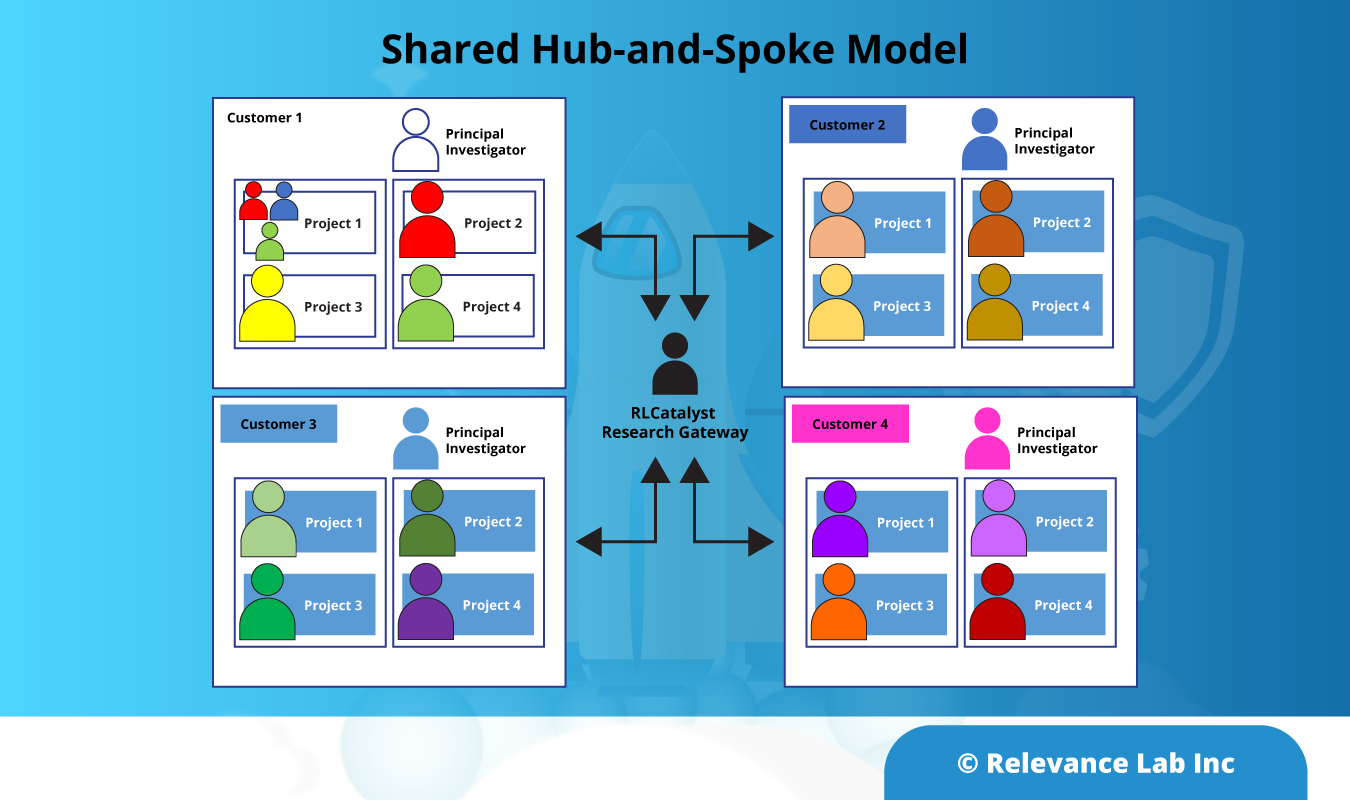
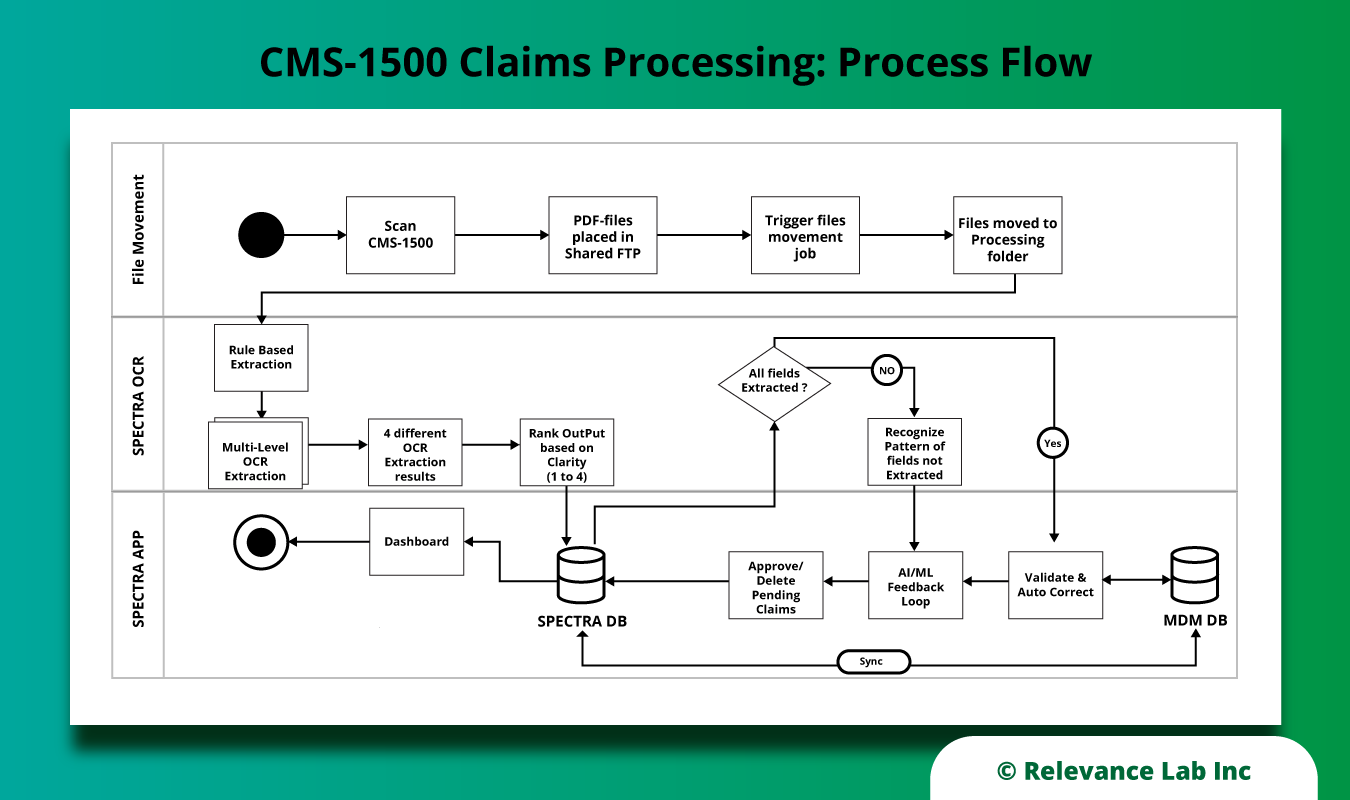
The following diagram presents a typical process flow incorporating our solution:
Demonstrated Benefits
Our CMS-1500 processing solution delivers significant time and cost savings, and quality improvements. It frees up teams from tedious tasks like data entry, without compromising human supervision and control over the process. The solution is scalable, keeping costs low even when processing volumes increase manifold.
The solution is tried, tested, and proven to deliver substantial value. For example, in a recent implementation at a renowned healthcare provider, the Relevance Lab SPECTRA solution was able to reduce the claims processing time by over 90%. Instead of a dedicated team working daily to process claim forms, manual intervention is now required only once a week for review and approvals. The resources freed up are now more productively utilized. This has also led to an increase in accuracy through the elimination of “human errors” such as typos.
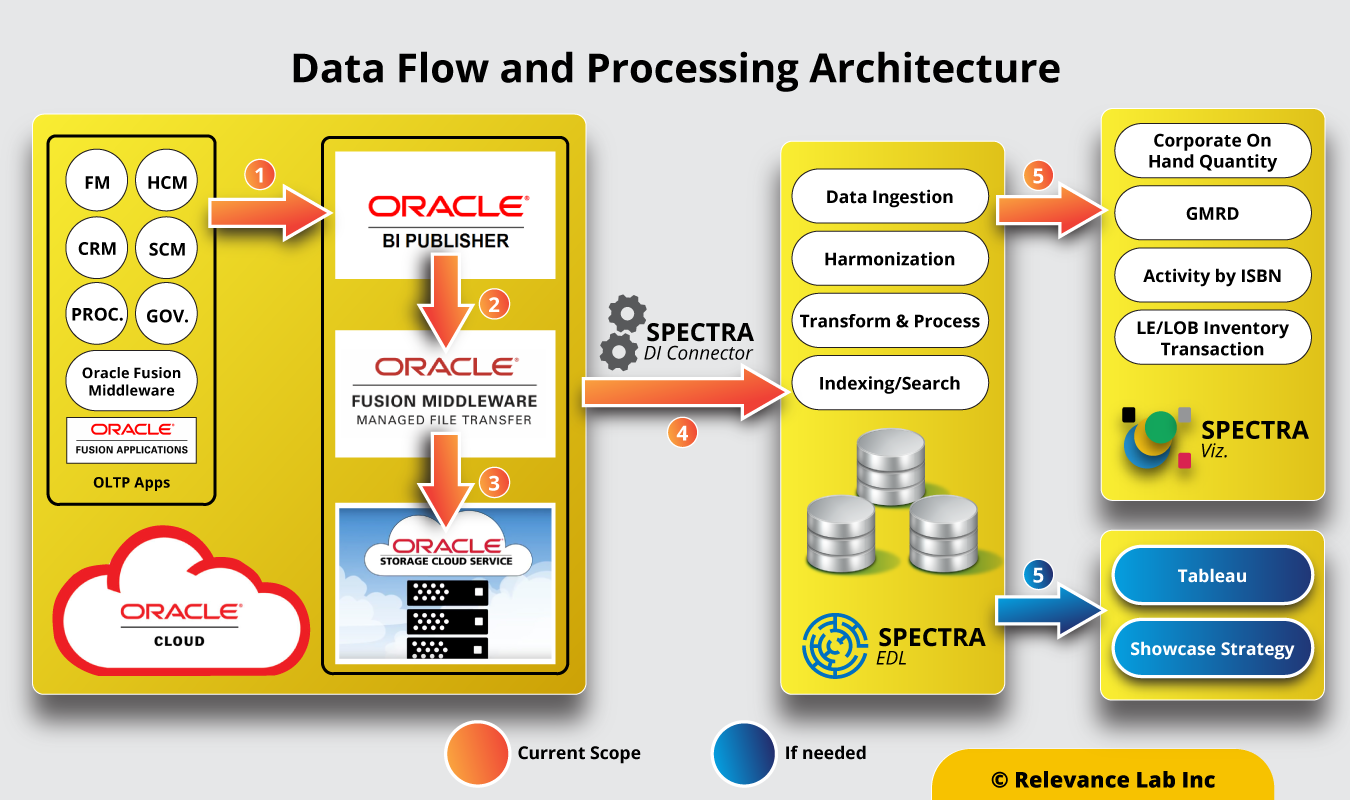
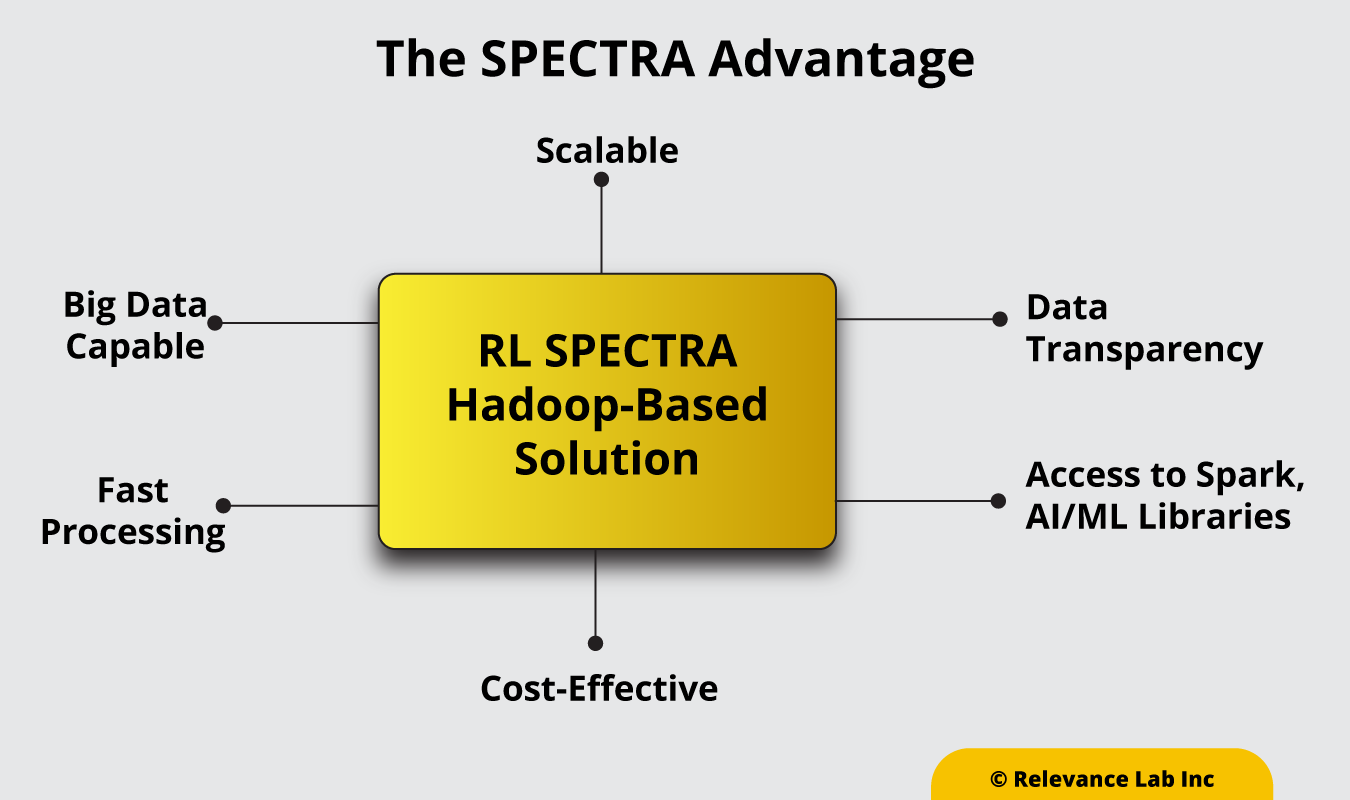
Powered by the RL SPECTRA analytics platform, the solution has successfully delivered productivity gains to multiple clients by efficiently ingesting and processing structured and unstructured data. The plug-and-play platform is easy to integrate with most common system environments and applications.
Conclusion
CMS-1500 claims processing can be significantly optimized by using Relevance Lab’s intelligent solution based on its SPECTRA platform that combines the speed and scalability of automation with the judgment of a human reviewer to deliver substantial productivity gains and cost savings to organizations.
For more details, please feel free to reach out to marketing@relevancelab.com.