CIGNEX and Excellerent today announced their merger with Relevance Lab, to become a global powerhouse in digital transformation and cloud services. With this merger, Relevance Lab, headquartered in Singapore, will have delivery presence across North America, India and Ethiopia and a global headcount of 1500+ employees. While Relevance Lab excels in DevOps/Automation on Infrastructure, Applications and Data, CIGNEX is a leader in Open-Source Technologies and Cloud that are used to engineer/deploy digital transformations & robotic process automation applications; and Excellerent, besides its Agile Engineering prowess, provides a unique differentiator with its development center in Ethiopia. The merger provides the platform economies of scale and an integrated approach to address all the dimensions of digital transformation from its global development centers. Incumbent management of the respective companies will continue in their new roles under the new CEO’s leadership.
With this merger, Vasu Sarangapani has joined Relevance Lab as it’s new President & CEO. Vasu comes with over 30 years of experience in Technology Services. Prior to this role, Vasu was with GlobalLogic Inc, where he was the Chief Growth Officer and prior to that, Chief Sales Officer of the company. In his tenure spanning 9 years, he helped expand the company’s global business significantly and played an instrumental role in providing multiple exits for the PE’s.
Explaining the rationale behind the merger, Vasu Sarangapani, incoming President & CEO, Relevance Lab, said, “Digital Transformation for enterprises is an existential necessity today and CXO’s want to accomplish this quickly by leveraging technology and partnerships to gain even the smallest competitive advantage. I strongly believe that the merged entity, with its deep technology expertise and assets driven approach, is well positioned to capture a big chunk of this digital services market and am very excited to be a part of this compelling story.”
“Given that the 3 companies had a common investor and the management team’s high levels of comfort working with each other over the years, it was only natural for us to merge as one company to unify our complementary technology offerings and service our customers. Under the leadership of Vasu, we look forward to rapidly increasing value creation for all stakeholders,” commented Raja Nagarajan, Founder & incumbent CEO, Relevance Lab.
About Relevance Lab
Relevance Lab is a specialized technology services company with technology assets in the DevOps, Cloud, Automation, Service Delivery and Agile Analytics domains. Using an asset leveraged delivery model, Relevance Lab helps global organizations achieve frictionless business transformation across Infrastructure, Applications and Data. For more details visit https://relevancelab.com
While there is rapid momentum for every enterprise in the world in consuming more Cloud Assets and Services, there is still lack of maturity in adopting an “Automation-First” approach to establish Self-Service models for Cloud consumptions due to fear of uncontrolled costs, security & governance risks and lack of standardized Service Catalogs of pre-approved Assets & Service Requests from Central IT groups. Lack of delegation and self-service has a direct impact on speed of innovation and productivity with higher operations costs.
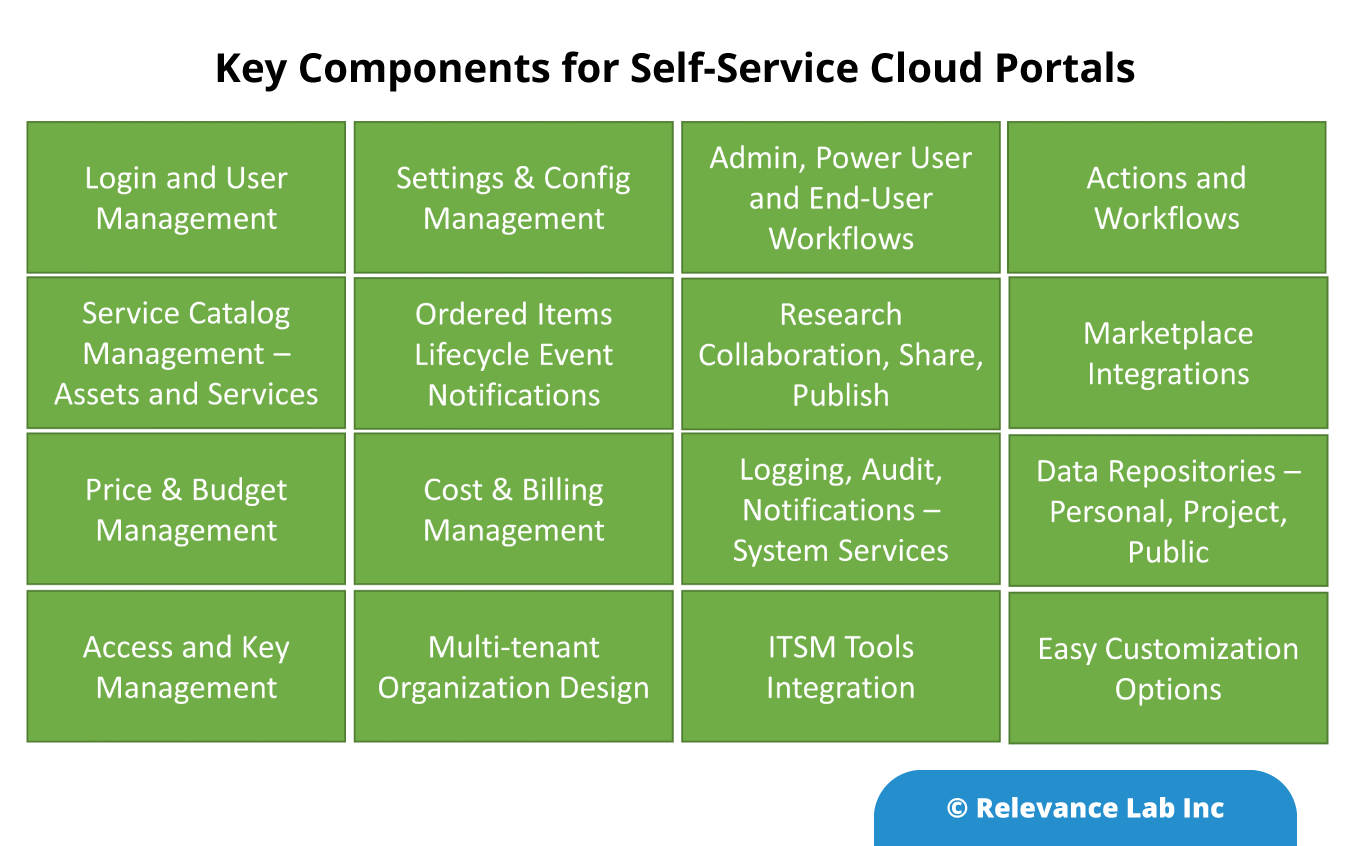
Working closely with AWS Partnership we have now created a flexible platform for driving faster adoption of Self-Service Cloud Portals. The primary needs for such a Self-Service Cloud Portal are the following.
Adherence to Enterprise IT Standards
Common architecture
Governance and Cost Management
Deployment and license management
Identity and access management
Common Integration Architecture with existing platforms on ITSM and Cloud
Support for ServiceNow, Jira, Freshservice and Standard Cloud platforms like AWS
Ability to add specific custom functionality in the context of Enterprise Business needs
The flexibility to add business specific functionality is key to unlocking the power of self-service models outside the standard interfaces already provided by ITSM and Cloud platforms
A common way of identifying the need for a Self-Service Cloud portal is based on following needs.
Does your enterprise already have any Self-Service Portals?
Do you have a large user base internally or with external users requiring access to Cloud resources?
Does your internal IT have the bandwidth and expertise to manage current workloads without impacting end user response time expectations?
Does your enterprise have a proper security governance model for Cloud management?
Are there significant productivity gains by empowering end users with Self-Service models?
Working with AWS partnership and an our existing customer, we see a growing need for Self-Service Cloud Portals in 2023 predominantly centred around two models.
Enterprises with existing ITSM investments and need to leverage that for extending to Cloud Management
Enterprises extending needs outside enterprise users with custom Cloud Portals
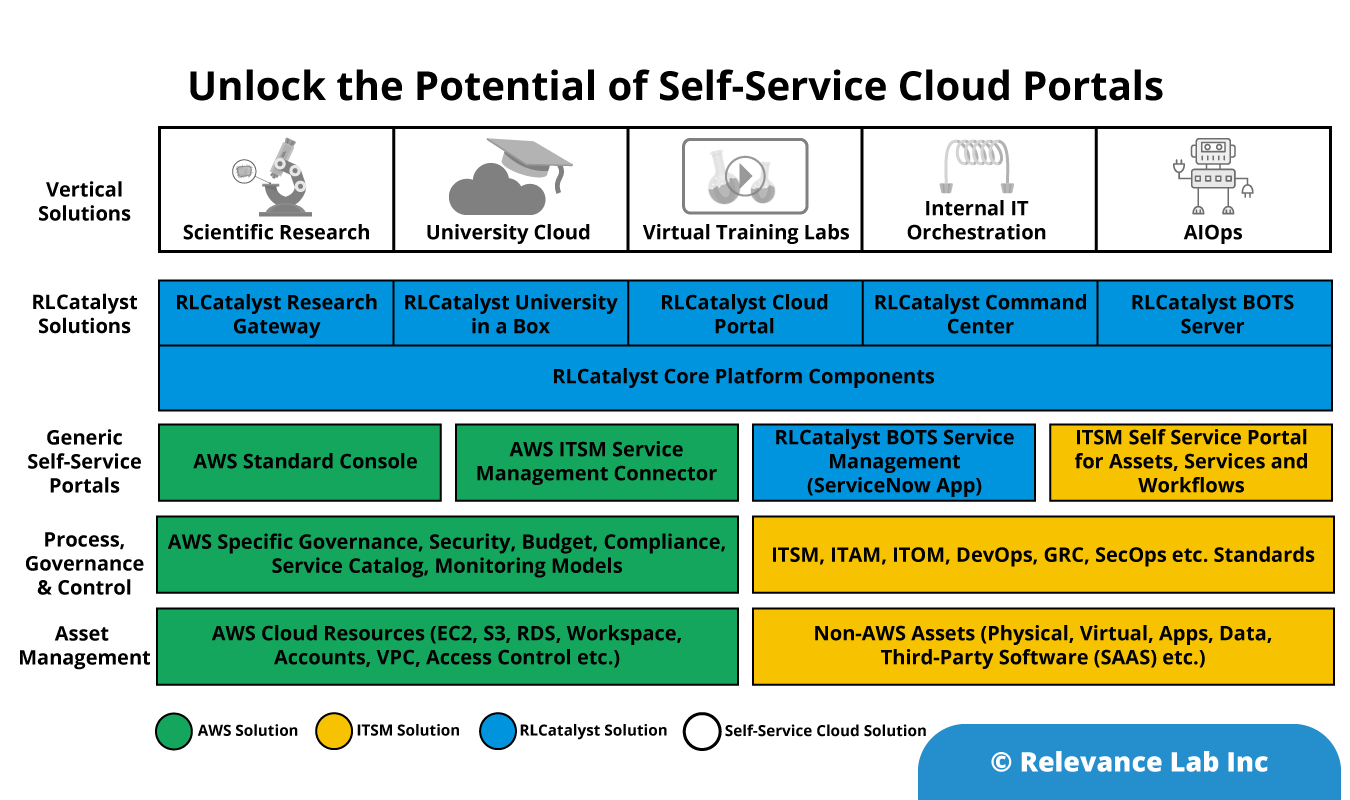
The roadmap to Self-Service Cloud portals is specific to every enterprise needs and needs to leverage the existing adoption and maturity of Cloud and ITSM platforms as explained below. With Relevance Lab RLCatalyst products we help enterprises achieve the maturity in a cost effective and expedited manner.
Professional and responsive UI Design with multiple themes available, customizations allowed
Standards based Architecture & Governance
Tightly Built On AWS products and AWS Well Architected with pre-built Reference Architecture based Products
Pre-built Minimum Viable Product Needs
80-20 Model – Pre-built vs Customizations based on key components of core functionality
Proprietary vs Open Source?
Open-source foundation with source code made available built on MEAN Stack
Access Control, Security and Governance
Standard Options Pre-built, easy extensions (SAML Based). Deployed with enterprise grade security and compliances
Rich Standard Pre-Build Catalog of Assets and Services
Comes pre-built with 100+ catalog items covering all standard Asset and Services needs catering to 50% of any enterprise infrastructure, applications and service delivery needs
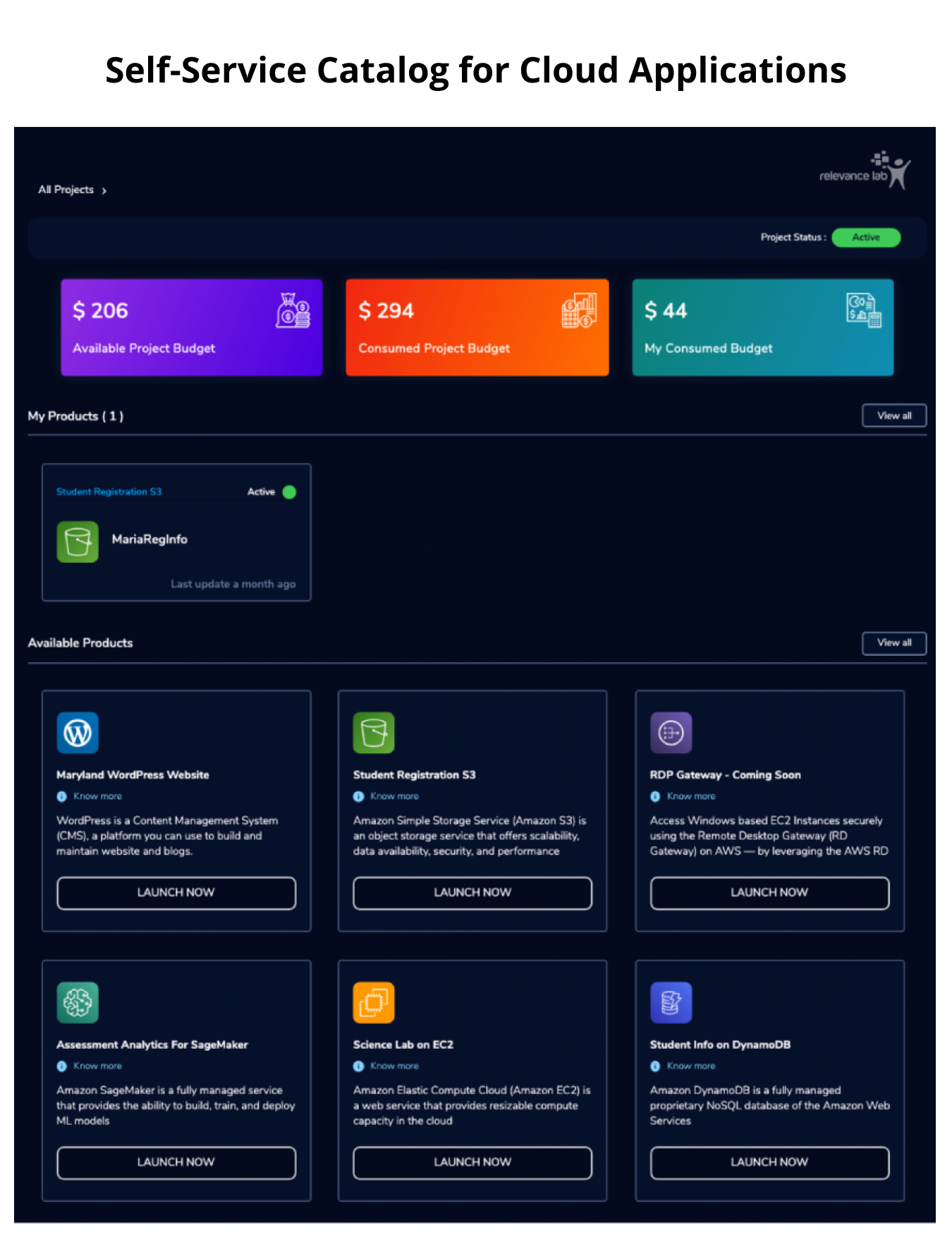
Explained below is a sample AWS Self-Service Cloud for driving Scientific Research.
Getting started
To make is easier for enterprises for experiencing the power of Self-Service Cloud Portals we are offering two options based on enterprise needs.
Hosted SAAS offering of using our Multi-tenant Cloud Portal with ability to connect to your existing Cloud Accounts and Service Catalogs
Self-Hosted RLCatalyst Cloud Portal product with option to engage us for professional services on customizations, training, initial setup & onboarding needs
Pricing for the SAAS offering is based on user based monthly subscription while for self-hosting model an enterprise support model pricing is available for the open source solution that allows enterprises the flexibility to use this solution without proprietary lock-ins.
The typical steps to get started are very simple covering the following.
Setup an organization and business units or projects aligned with your Cloud Accounts for easy billing and access control tracking
Setup users and roles
Setup Budgets and controls
Setup standard catalog of items for users to order
With the above enterprises are up to speed to use Self-Service Cloud Portals in less than 1-Day with inbuilt controls for tracking and compliance
Summary
Cloud Portals for Self-Service is a growing need in 2023 and we see the momentum continuing for next year as well. Different market segments have different needs for Self-Service Cloud portals as explained in this Blog.
Scientific Research community is interested in a Research Gateway Solution
University IT looks for a University in a Box Self-Service Cloud
Enterprises using ServiceNow want to extend the internal Self-Service Portals
Enterprises are also developing Hybrid Cloud Orchestration Portals
Enterprises looking at building AIOps Portal needs monitoring, automation and service management
Enabling Virtual Training Labs with User and Workspace onboarding
Building an integrated Command Centre requires an Intelligent Monitoring portal
Enterprise Intelligent Automation Portal with ServiceNow Connector
We provide pre-build solutions for Self-Service Cloud Portals and a base platform that can be easily extended to add new functionality for customization and integration. A number of large enterprises and universities are leveraging our Self-Service Cloud portal solutions using both existing ITSM tools (Servicenow, Jira, Freshservice) and RLCatalyst products.
To learn more about using AWS Cloud or ITSM solutions for Self-Service Cloud portals contact
marketing@relevancelab.com
Relevance Lab (RL) is a specialist company in helping customers adopt cloud “The Right Way” by focusing on an “Automation-First” and DevOps strategy. It covers the full lifecycle of migration, governance, security, monitoring, ITSM integration, app modernization, and DevOps maturity. Leveraging a combination of services and products for cloud adoption, we help customers on a “Plan-Build-Run” transformation that drives greater velocity of product innovation, global deployment scale, and cost optimization for new generation technology (SaaS) and enterprise companies.
In this blog, we will cover some common themes that we have been using to help our customers for cloud adoption as part of their maturity journey.
SaaS with multi-tenant architecture
Multi-Account Cloud Management for AWS
Microservices architecture with Docker and Kubernetes (AWS EKS)
Jenkins for CI/CD pipelines and focus on cloud agnostic tools
AWS Control Tower for Cloud Management & Governance solution (policy, security & governance)
DevOps maturity models
Cost optimization, agility, and automation needs
Standardization for M&A (Merger & Acquisitions) integrations and scale with multiple cloud provider management
Spectrum of AWS governance for optimum utilization, robust security, and reduction of budget
Automation/BOT landscape, how different strategies are appropriate at different levels, and the industry best practice adoption for the same
Reference enterprise strategy for structuring DevOps for engineering environment which has cloud native development and the products which are SaaS-based.
Relevance Lab Cloud and DevOps Credentials at a Glance
RL has been a cloud, DevOps, and automation specialist since inception in 2011 (10+ years)
Need for a Comprehensive Approach to Cloud Adoption
Most enterprises today have their applications in the cloud or are aggressively migrating new ones for achieving the digital transformation of their business. However, the approach requires customers to think about the “Day-After” Cloud in order to avoid surprises on costs, security, and additional operations complexities. Having the right Cloud Management not only helps eliminate unwanted costs and compliance, but it also helps in optimal use of resources, ensuring “The Right Way” to use the cloud. Our “Automation- First Approach” helps minimize the manual intervention thereby, reducing manual prone errors and costs.
RL’s matured DevOps framework helps in ensuring the application development is done with accuracy, agility, and scale. Finally, to ensure this whole framework of Cloud Management, Automation and DevOps are continued in a seamless manner, you would need the right AIOps-driven Service Delivery Model.
Hence, for any matured organizations, the below 4 themes become the foundation for using Cloud Management, Automation, DevOps, and AIOps.
Cloud Management
RL offers a unique methodology covering Plan-Build-Run lifecycle for Cloud Management, as explained in the diagram below.
Following are the basic steps for Cloud Management:
Step-1: Leverage
Built on best practices offered from native cloud providers and popular solution frameworks, RL methodology leverages the following for Cloud Management:
AWS Well-Architected Framework
AWS Management & Governance Lens
AWS Control Tower for large scale multi-account management
AWS Service Catalog for template-driven organization standard product deployments
Terraform for Infra as Code automation
AWS CloudFormation Templates
AWS Security Hub
Step-2: Augment
The basic Cloud Management best practices are augmented with unique products & frameworks built by RL based on our 50+ successful customer implementations covering the following:
Quickstart automation templates
AppInsights and ServiceOne – built on ITSM
RLCatalyst cloud portals – built on Service Catalog
Governance360 – built on Control Tower
RLCatalyst BOTS Automation Server
Step-3: Instill
Instill ongoing maturity and optimization using the following themes:
Four level compliance maturity model
Key Organization metrics across assets, cost, health, governance, and compliance
Industry-proven methodologies like HIPAA, SOC2, GDPR, NIST, etc.
For Cloud Management and Governance, RL has Solutions like Governance360, AWS Management and Governance lens, Cloud Migration using CloudEndure. Similarly, we have methodologies like “The Right Way” to use the cloud, and finally Product & Platform offerings like RLCatalyst AppInsights.
Automation
RL promotes an “Automation-First” approach for cloud adoption, covering all stages of the Plan-Build-Run lifecycle. We offer a mature automation framework called RLCatalyst BOTs and self-service cloud portals that allow full lifecycle automation.
In terms of deciding how to get started with automation, we help with an initial assessment model on “What Can Be Automated” (WCBA) that analyses the existing setup of cloud assets, applications portfolio, IT service management tickets (previous 12 months), and Governance/Security/Compliance models.
For the Automation theme, RL has Solutions like Automation Factory, University in a Box, Scientific Research on Cloud, 100+ BOTs library, custom solutions on Service WorkBench for AWS. Similarly, we have methodologies like Automation-First Approach, and finally Product & Platform offerings like RL BOTs automation Engine, Research Gateway, ServiceNow BOTs Connector, UiPath BOTs connector for RPA.
The following blogs explain in more detail our offerings on automation.
DevOps and Microservices
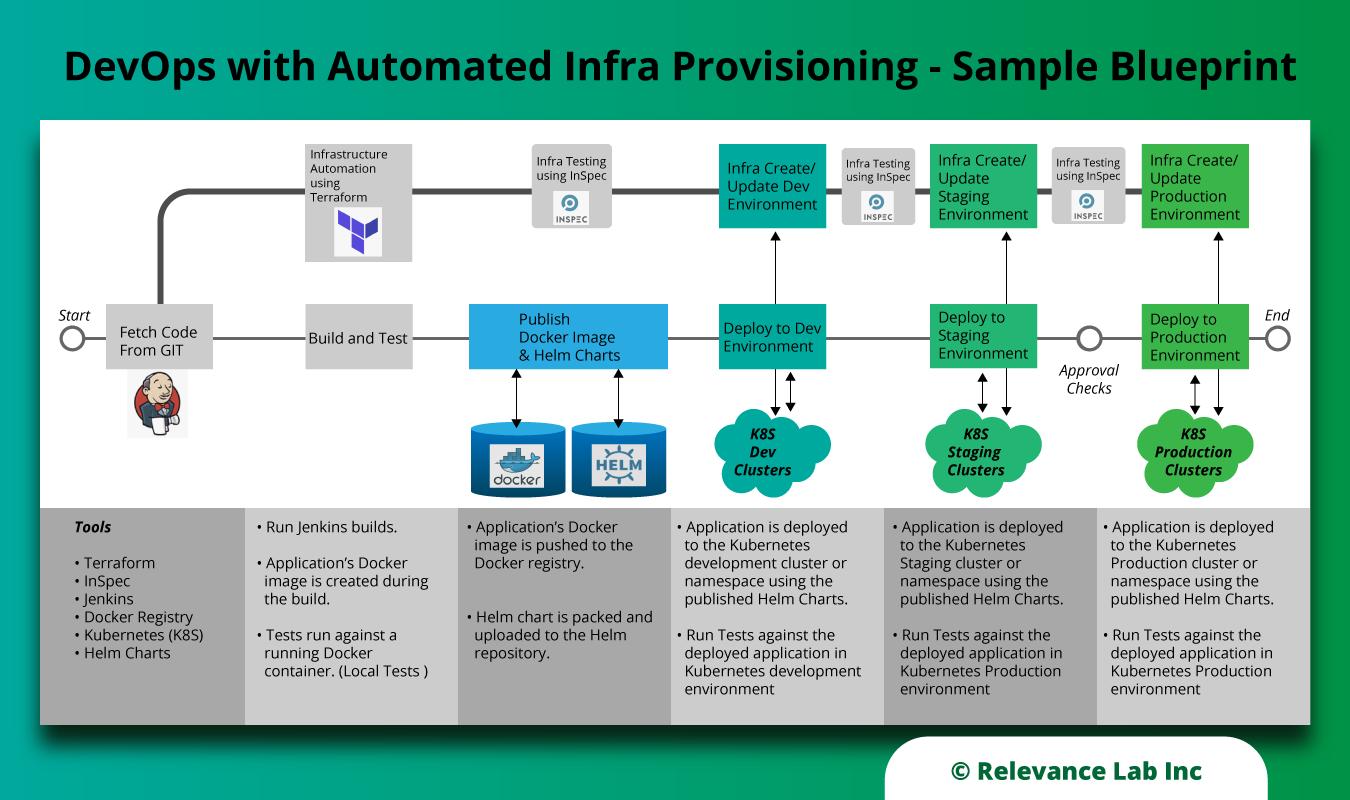
DevOps and microservices with containers are a key part of all modern architecture for scalability, re-use, and cost-effectiveness. RL, as a DevOps specialist, has been working on re-architecting applications and cloud migration across different segments covering education, pharma & life sciences, insurance, and ISVs. The adoption of containers is a key building block for driving faster product deliveries leveraging Continuous Integration and Continuous Delivery (CI/CD) models. Some of the key considerations followed by our teams cover the following for CI/CD with Containers and Kubernetes:
Role-based deployments
Explicit declarations
Environment dependent attributes for better configuration management
Order of execution and well-defined structure
Application blueprints
Repeatable and re-usable resources and components
Self contained artifacts for easy portability
The following diagram shows a standard blueprint we follow for DevOps:
For the DevOps & Microservices theme, RL has Solutions like CI/CD Cockpit solution, Cloud orchestration Portal, ServiceNow/AWS/Azure DevOps, AWS/Azure EKS. Similarly, we have methodologies like WOW DevOps, DevOps-driven Engineering, DevOps-driven Operations, and finally Product & Platform offerings like RL BOTs Connector.
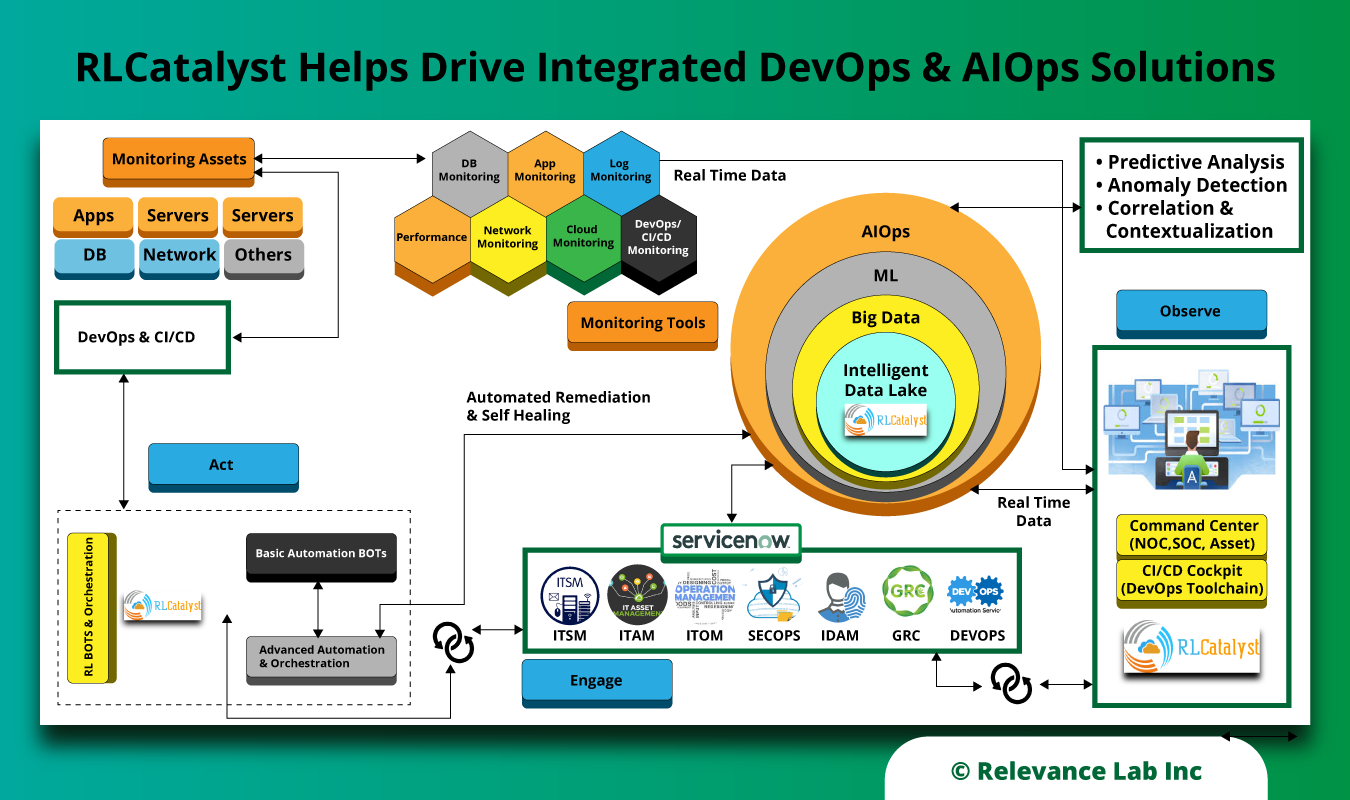
AIOps and Service Delivery
RL brings in unique strengths across AIOps with IT Service Delivery Management on platforms like ServiceNow, Jira ServiceDesk and FreshService. By leveraging a platform-based approach that combines intelligent monitoring, service delivery management, and automation, we offer a mature architecture for achieving AIOps in a prescriptive manner with a combination of technology, tools, and methodologies. Customers have been able to deploy our AIOps solutions in 3 months and benefit from achieving 70% automation of inbound requests, reduction of noise on proactive monitoring by 80%, 3x faster fulfillment of Tickets & SLAs with a shift to a proactive DevOps-led organization structure.
For the AIOps & Service Delivery theme, RL has Solutions like AIOps Blueprint, ServiceNow++, End to End Automated Patch Management, Asset Management NOC & ServiceDesk. Similarly, we have methodologies like ServiceOne and finally Product & Platform offerings like ServiceOne with ServiceNow, ServiceOne with FreshService, RLCommand Center.
Summary
RL offers a combination of Solutions, Methodologies, and Product & Platform offerings covering the 360 spectrum of an enterprise Cloud & DevOps adoption across 4 different tracks covering Cloud Management, Automation, DevOps, and AIOps.
The benefits of a technology-driven approach that leverages an “Automation-First” model has helped our customer reduce their IT spends by 30% over a period of 3 years with 3x faster product deliveries and real-time security & compliance.
To know more about our Cloud Centre of Excellence and how we can help you adopt Cloud “The Right Way” with best practices leveraging Cloud Management, Automation, DevOps, and AIOps, feel free to write to marketing@relevancelab.com
The Consumer Packaged Goods (CPG) Industry is one of the largest industries on the planet. From food and beverage to clothes to stationary, it is impossible to think of a moment in our lives without being touched or influenced by this sector. If there is one paradigm around which the industry revolves, regardless of the sub-sector or the geography, it is the fear of stock outs. Studies indicate that when a customer finds a product unavailable, 31% are likely to switch over to a competitor when it happens for the first time. It becomes 50% when this occurs for a second time and rises to 70% when this happens for a third time.
Historically, the panacea for this problem has been to overstock. While this reduced the risk of stock outs to a great extent, it induced a high cost for holding the inventory and increased risk of obsolescence. It also created a shortage of working capital since a part of it is always locked away in holding excess inventory. This additional cost is often passed on to the end customer. Over time, an integrated planning solution which could predict demand, supply and inventory positions became a key differentiator in the CPG industry since it helped rein in costs and become competitive in an industry which is extremely price sensitive.
Although theoretically, a planning solution should have been able to solve the inventory puzzle, practically, a lot of challenges kept limiting its efficacy. Conventional planning solutions have been built based on local planning practices. Such planning solutions have had challenges negotiating the complex demand patterns of the customers which are influenced by general consumer behaviour and also seasonal trends in the global market. As a result the excess inventory problem stays, which gets exacerbated at times due to bullwhip effect.
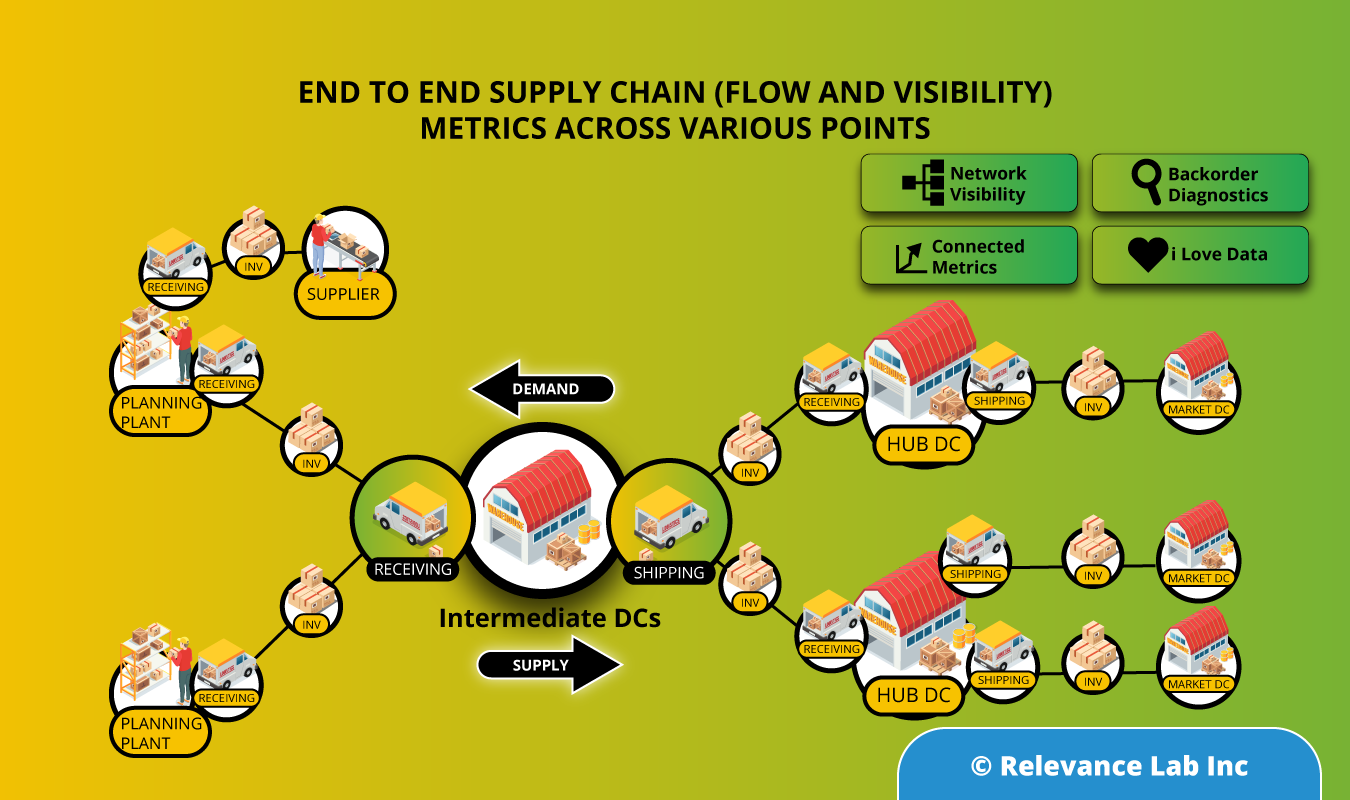
This is where the importance of a global integrated Production Sales Inventory (PSI) solutions comes in. But usually, this is easier said than done. Large organizations face multiple practical challenges when they attempt to implement this. Following are the typical challenges that large organizations face
Infrastructural Limitations Using conventional systems of Business Intelligence of Planning systems would require very heavy investment in infrastructure and systems. Also the results may not be proportionate to the investments made.
Data Silos
PSI requires data from different departments including sales, production, and procurement/sourcing. Even if the organization has a common ERP, the processes and practices in each department might make it difficult to combine data and get insights.
Another significant hurdle is the fact that larger organizations usually tend to have multiple ERPs for handling local transactions aligned to geographical markets. Each ERP or data source which does not talk to other systems becomes siloed. The complexities increase when the data formats and tables are incompatible, especially, when the ERPs are from different vendors.
Manual Effort
Harmonizing the data from multiple systems and making them coherent involves a huge manual effort in designing, building, testing and deployment if we follow conventional mode. The prohibitive costs involved, not to mention the human effort involved is a huge challenge for most organizations.
Relevance Lab has helped multiple customers tide over the above challenges and get a faster return on their investments.
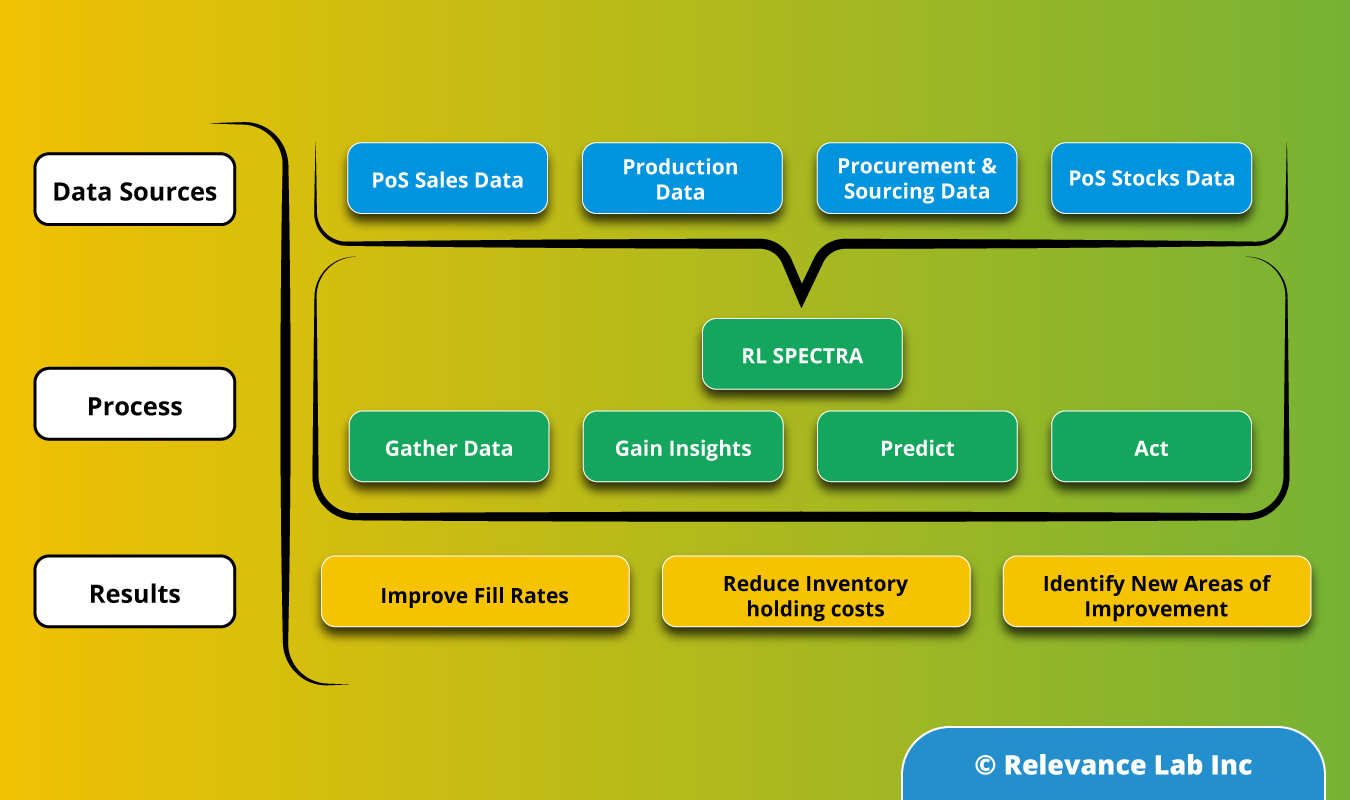
Here are the steps we follow to achieve a responsive global supply chain
Gather Data: Collate data from all relevant systems
Leveraging data from as many relevant sources (both internal and external) as possible is one of the most important steps in ensuring a responsive global supply chain. The challenge of handling the huge data volume is addressed through the use of big data technologies.
The data gathered is then cleansed and harmonized using SPECTRA, Relevancelab big data/analytics platform. SPECTRA can then combine the relevant data from multiple sources, and refresh the results at specified periodic intervals.
One point of note here is that Master Data harmonization, that usually consumes months of effort can be significantly accelerated with the SPECTRA’s machine learning and NLP capabilities.
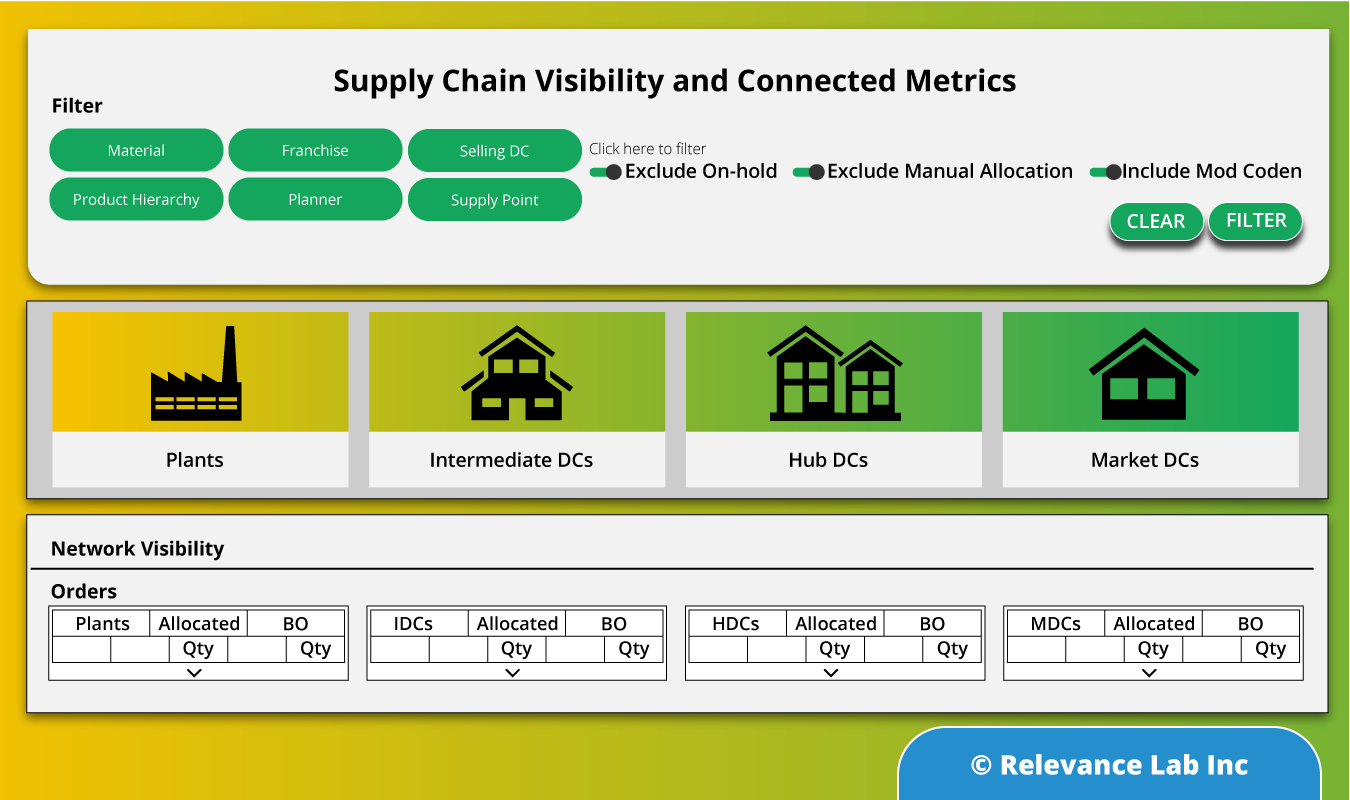
Gain Insights: Know the as-is states from intuitive visualizations
The data pulled in from various sources can be combined to see the snapshot of inventory levels across the supply chain. SPECTRA’s built-in data models and quasi plug and play visualizations ensure that users get a quick and accurate picture of their supply chain. Starting with a bird’s eye view of the current inventory levels across various types of stocking locations and across each inventory type, the visualization capabilities of SPECTRA can be leveraged to have a granular view of the current inventory positions or backlog orders or compare sales with the forecasts. This a critical step in the overall process as this helps organizations to clearly define their problems and identify likely end states. For example, the organization could go for a deeper analysis to identify slow moving and obsolete inventory or fine tune their planning parameters.
Predict: Use big data to predict inventory levels
The data from various systems can be used to predict the likely inventory levels based on service level targets, demand predictions, production and procurement information. Time series analysis is used to predict the lead time for production and procurement.
Projected inventory level calculations for future days/weeks, thus calculated, is more likely to reflect the actual inventory levels since the uncertainties, both external and internal, have been well accounted for.
Act: Measurement and Continuous Improvement
Inventory management is a continuous process. The above steps would provide a framework for measuring and tracking the performance of the inventory management solution and make necessary course corrections based on real time feedback.
Conclusion
Successful inventory management is one of the basic requirements for financial success for companies in the Consumer Packaged Goods Sector. There is no perfect solution to achieve this as the customer needs and environment are dynamic and the optimal solution could only be reached iteratively. Relevancelab framework to address inventory management combining deep domain experience with SPECTRA’s capabilities like NLP for faster master data management & harmonization, pre-built data models, quasi plug and play visualizations and custom algorithms offer a faster turn-around and quicker Return-on-Investment. Additionally, the comprehensive process ensures that the data is massaged and prepped for both broader and deeper analysis of the supply chain and risk in the future.
In our increasingly digitized world, companies across industries are embarking on digital transformation journeys to transform their infrastructure, application architecture and footprint to a more modern technology stack, one that allows them to be nimble and agile when it comes to maintainability, scalability, easier deployment (smaller units can be deployed frequently).
Old infrastructure and the traditional ways of building applications are inhibiting growth for large enterprises, mid-sized and small businesses. Rapid innovation is needed to rollout new business models, optimize business processes, and respond to new regulations.
Business leaders and employees understand the need for this agility – everyone wants to be able to connect to their Line of Business (LOB) systems through mobile devices or remotely in a secure and efficient manner, no matter how old or new these systems are, and this is where Application Modernization comes in to picture.
A very interesting use case was shared with us by our large Financial Asset management customer. They had a legacy application, which was 15+ years old and having challenges like tightly coupled business modules, code base/solution maintainability, complexity in implementing lighter version of workflow, modular way of deploying key features, legacy technology stack based application, etc. To solve this problem we had a solid envisioning phase for future state application by considering the next generation solution architecture approach, latest technology stack, value add for the business – lighter version of workflow engine, responsive design & End–to–End (E2E) DevOps solution.
Legacy Application Modernizations/Platform Re-Engineering
Legacy application modernization projects intend to create new business value from existing, aging applications by updating or replacing them with modern technologies, features and capabilities. By migrating the legacy applications, business can include the latest functionalities that better align with where business needs transformation & success.
These initiatives are typically designed and executed with phased rollouts that will replace certain functional feature sets of the legacy application with each successive rollout, eventually evolving into a complete, new, agile, modern application that is feature-rich, flexible, configurable, scalable and maintainable in future.
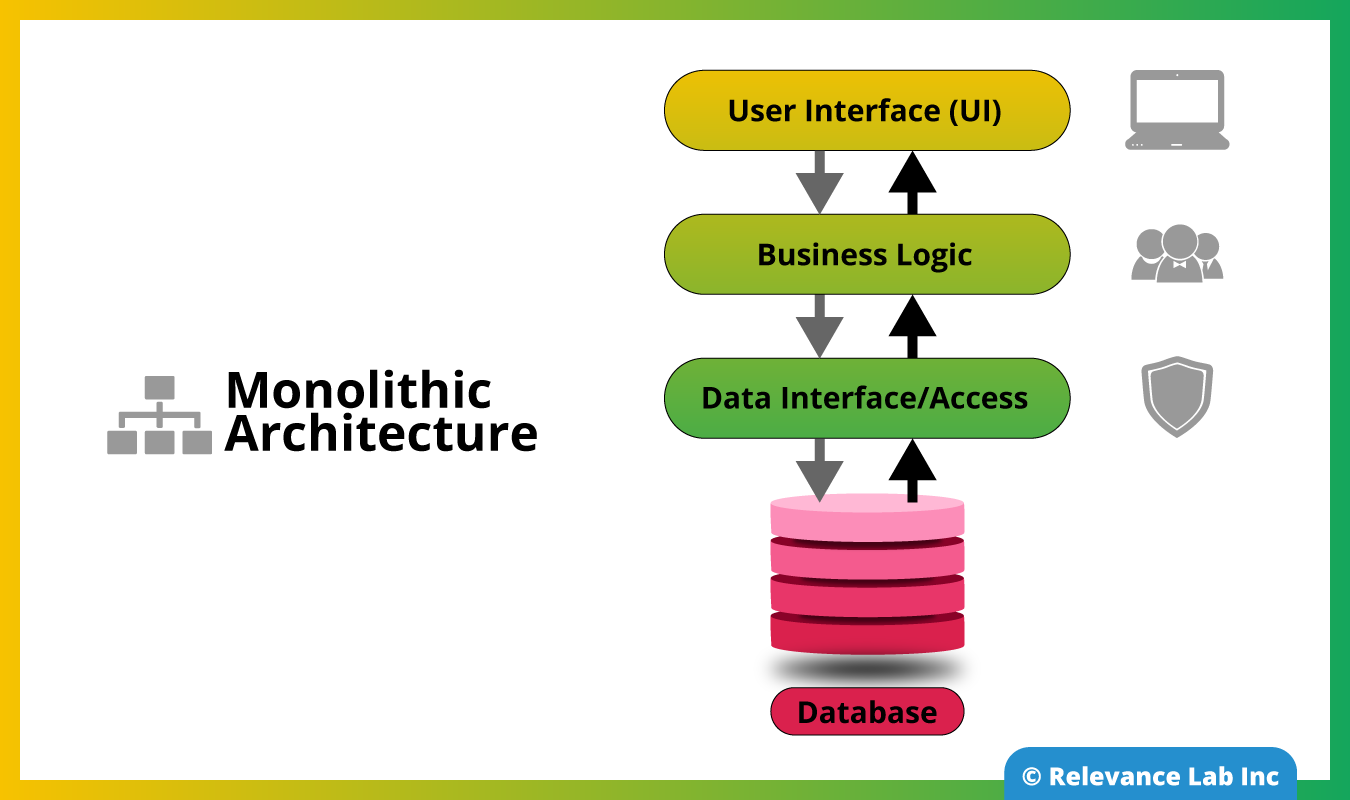
Monolithic Architecture Vs Microservices Architecture – The Big Picture
Monolithic Architecture
Traditional way of building applications
An application is built as one large system and is usually one codebase
Application is tightly coupled and gets entangled as the application evolves
Difficult to isolate services for purposes such as independent scaling or code maintainability
Usually deployed on a set of identical servers behind a load balancer
Difficult to scale parts of the application selectively
Usually have one large code base and lack modularity. If developers community wants to update or change something, they access the same code base. So, they make changes in the whole stack at once
The following diagram depicts an application built using Monolithic Architecture
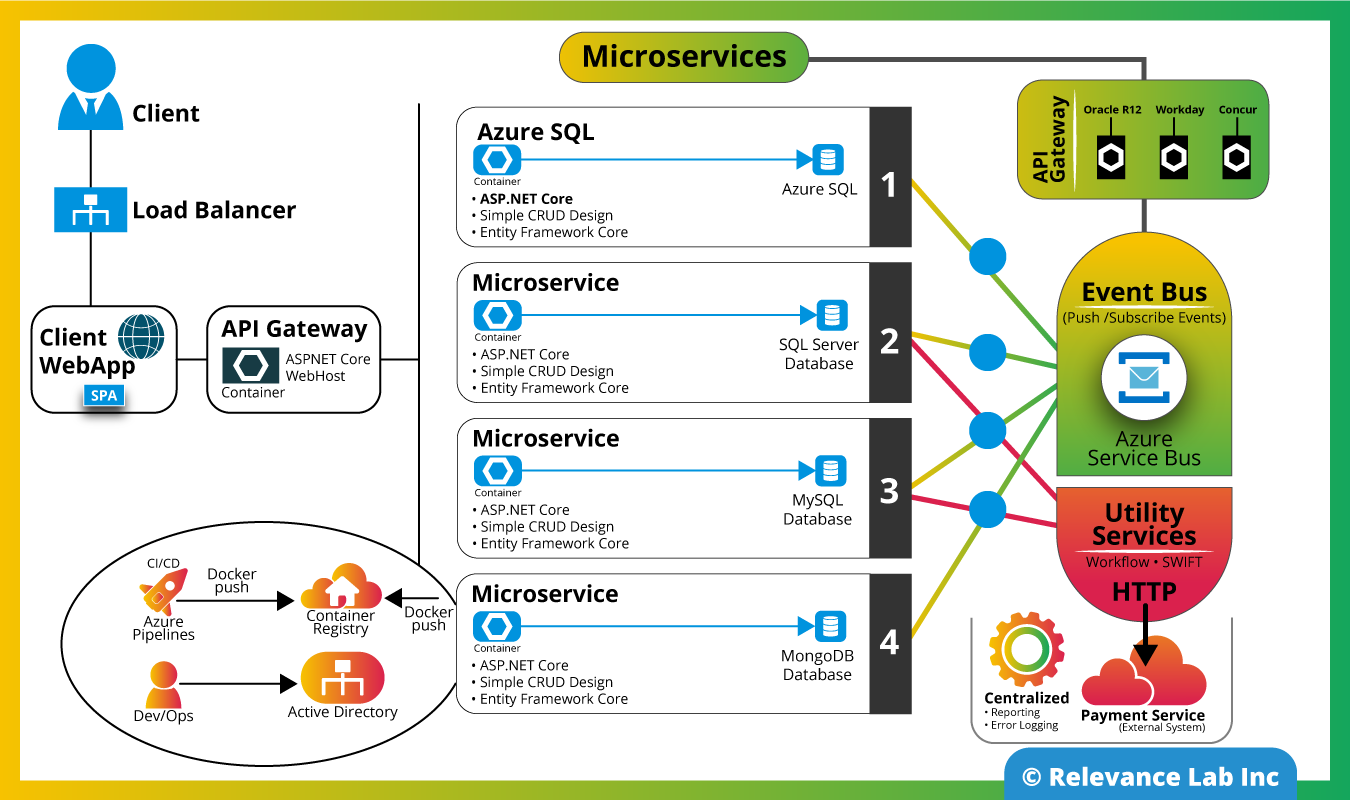
Microservices Architecture
Modern way of building applications
A microservice application typically consists of many services
Each service has multiple runtime instances
Each service instance needs to be configured, deployed, scaled, and monitored
Microservices Architecture – Tenets
The Microservices Architecture breaks the Monolithic application into a collection of smaller, independent units. Some of the salient features of Microservices are
Highly maintainable and testable
Autonomous and Loosely coupled
Independently deployable
Independently scalable
Organized around domain or business capabilities (context boundaries)
Owned by a small team
Owning their related domain data model and domain logic (sovereignty and decentralized data management) and could be based on different data storage technologies (SQL, NoSQL) and different programming languages
The following diagram depicts an enterprise application built using Microservices Architecture by leveraging Microsoft technology stack.
Benefits of Microservices Architecture
Easier Development & Deployment – Enables frequent deployment of smaller units. The microservices architecture enables the rapid, frequent, and reliable delivery of large, complex applications
Technology adoption/evolution – Enables an organization to evolve its technology stack
Process Isolation/Fault tolerance – Each service runs in its own process and communicates with other processes using standard protocols such as HTTP/HTTPS, Web Sockets, AMQP (Advanced Message Queuing Protocol)
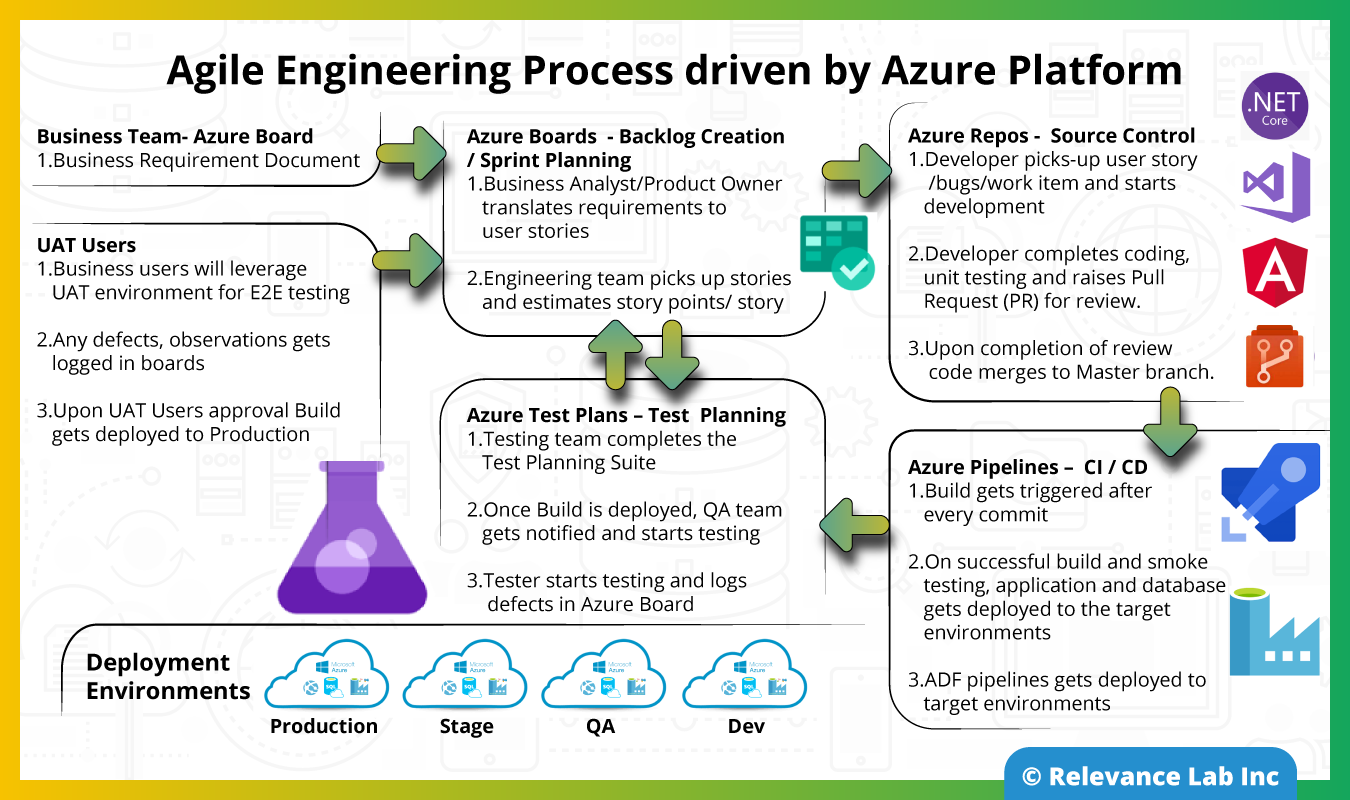
Today the Enterprise customers across the globe like eBay, GE Healthcare, Samsung, BMW, Boeing, etc. has been adopted Microsoft Azure platform for developing their Digital solutions. We at Relevance Lab also delivered numerous Digital transformational initiatives to our global customers by leveraging Azure platform and Agile scrum delivery methodology.
The following diagram depicts an enterprise solution development life cycle leveraging Azure platform and it’s various components, which enables Agile scrum methodology for the E2E solution delivery
Conclusion
Monolithic Architecture does have its strengths like development and deployment simplicity, easier debugging and testing and fewer cross-cutting concerns and can be a good choice for certain situations, typically for smaller applications.However, for larger, business critical applications, the monolithic approach can bring up challenges like technological barriers, scalability, tight coupling (rigidity) and hence makes it difficult to make changes, and development teams find them difficult to understand.
By adopting Microservices architecture and Microsoft Azure Platform based solutions business could leverage below benefits
Easier, rapid development of enterprise solutions
Global team could be distributed to focus certain services development of the system
Organized around business capabilities, rapid infrastructure provisioning & application development – Technology team will be focused not just on technologies but also acquires business domain knowledge, organized around business capabilities and cloud infrastructure provisioning/ capacity planning knowledge
Offers modularizations for large enterprise applications, increases productivity and helps distributed team to focus on their specific modules and deliver them in speed and scale them based on the business growth
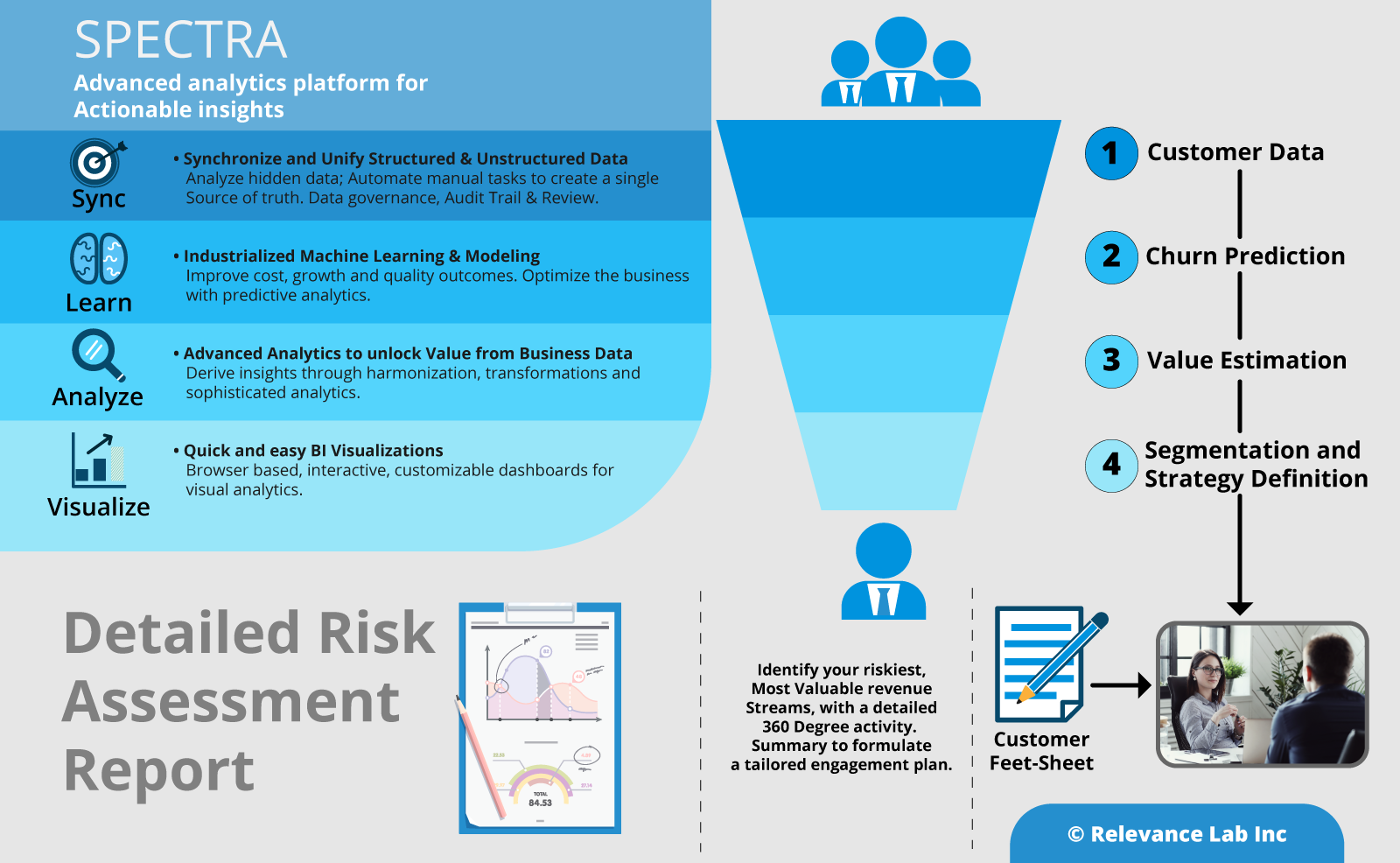
If you are a business with a digital product or a subscription model, then you are already familiar with this key metric – “Customer Churn”.
Customer Churn is the percentage of customers who stopped using your product during a given period. This is a critical metric, as it not only reflects customer satisfaction but it also has a big impact on your bottom line. A common rule of the thumb is that it costs 6-7 times to get a new customer versus keeping the customers you already have. In addition, existing customers are expected to spend more over time, and satisfied customers lead to additional sales through referrals. Market studies show that increasing customer retention by small percentage can boost revenues significantly. Further research reveals that most professionals consider that Churn is just as or more important a metric than new customer acquisitions.
Subscription businesses strongly believe customers cancel for reasons that could be managed or fixed. “Customer Retention” is the set of strategies and actions that a company follows to keep existing customers from churning. Employing a data-driven customer retention strategy, and leveraging the power of big data and machine learning, offer significant opportunities for businesses to create a competitive advantage versus their peers that don’t.
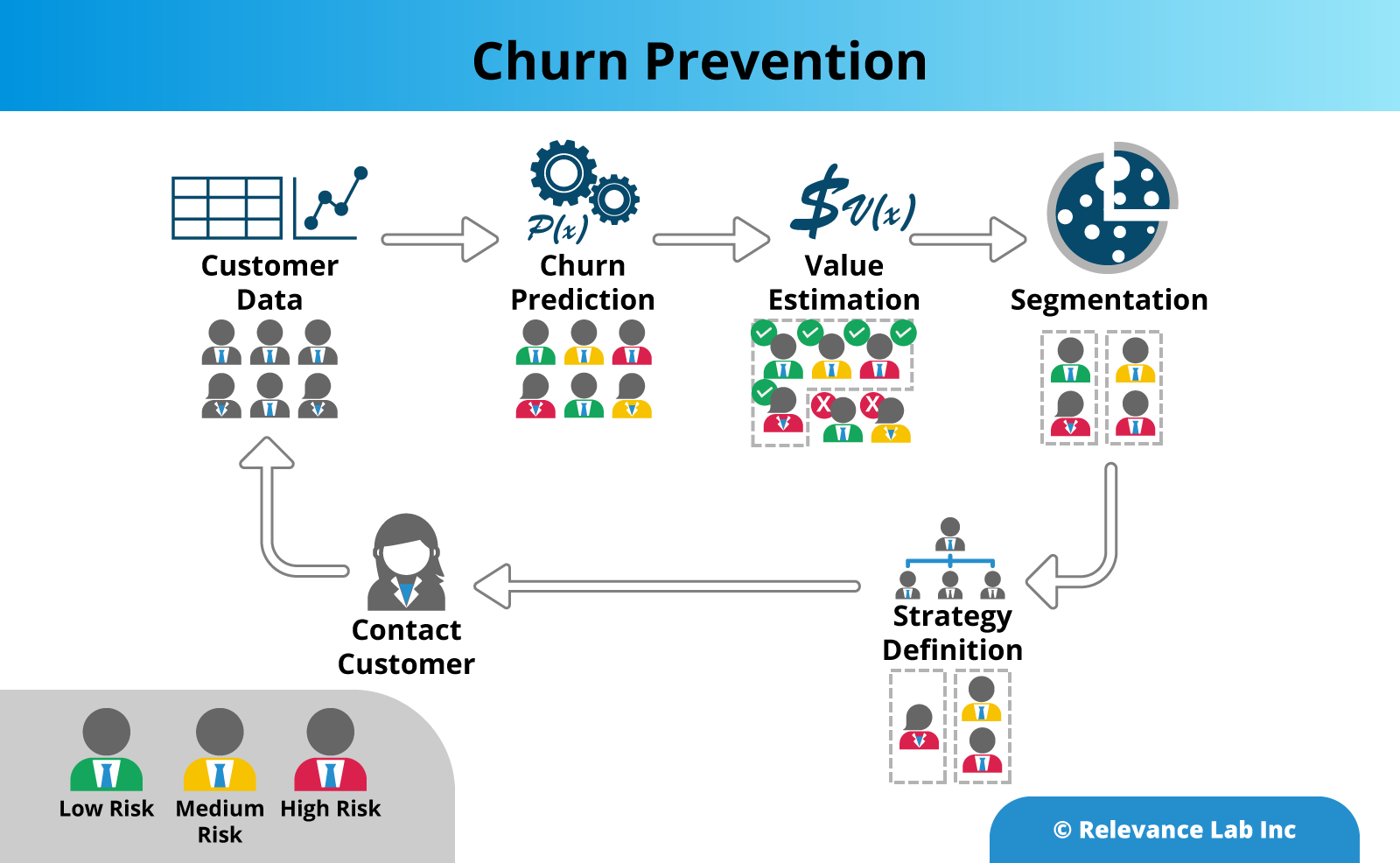
Relevance Lab (RL) recently helped a large US based Digital learning company benefit from a detailed churn analysis of its subscription customers, by leveraging the RL SPECTRA platform with machine learning. The portfolio included several digital subscription products used in school educational curriculums which are renewed annually during the start of the school calendar year. Each year, there were several customers that did not renew their licenses and importantly, this happened at the end of the subscription cycle; typically too late for the sales team to respond effectively.
Here are the steps that the organisation took along the churn management journey.
Gather multiple data points to generate better insights
As with any analysis, to figure out where your churn is coming from, you need to keep track of the right data. Especially with machine learning initiatives, the algorithms depend on large quantities of raw data to learn complex patterns. A sample list of data attributes could include online interactions with the product, clicks, page views, test scores, incident reports, payment information, etc, it could also include unstructured data elements such as reports, reviews and blog posts.
In this particular example, the data was pulled from four different databases which contained the product platform data for our relevant geography. Data collected included product features, sales and renewal numbers, as well as student product usage, test performance statistics etc, going back to the past 4 years.
Next, the data was cleansed to remove trial licenses, dummy tests etc, and to normalize missing data. Finally, the data was harmonized to bring all the information into a consolidated format.
All the above pipelines were established using the SPECTRA ETL process. Now there was a fully functional data setup with cleaned data ordered in tables, to be used in the machine learning algorithms for churn prediction.
Predictive analytics use Machine Learning to know who is at risk
Once you have the data, you are now ready to work on the core of your analysis, to understand where the risk of churn is coming from, and hence identify the opportunities for strengthening your customer relationships. Machine learning techniques are especially suited to this task, as they can churn massive amounts of historical data to learn about customer behavior, and then use this training to make predictions about important outcomes such as retention.
On our assignment, the RL team tried out a number of machine learning models built-in within SPECTRA to predict the churn and zeroed in on a random forest model. This method is very effective when using inconsistent data sets, where the system can handle differences in behavior very effectively by creating a large number of random trees. In the end, the system provided a predicted rating for each customer to drop out of the system and highlighted the ones most at risk.
Define the most valuable customers
Parallel to identifying customers at risk of churn, data can also be used to segment customers into different groups to identify how each group interacts with your product. In addition, data regarding frequency of purchase, purchase value, product coverage helps you to quickly identify which type of customers are driving the most revenue, versus customers which are a poor fit for your product. This will then allow you to adopt different communication and servicing strategies for each group, and to retain your most valuable customers.
By combining our machine learning model output with the segmentation exercise, the result was a dynamic dashboard, which could be sorted/filtered by different criteria such as customer size and geographical location. This provided the opportunity to highlight the customers which were at the highest risk, from the joint viewpoint of attrition and revenue loss. This in turn enabled the client to effectively utilize sales team resources in the best possible manner.
Engage with the customers
Now that you have identified your top customers who you are at risk of losing, the next step is to actively engage with them, to incentivise the customers to stay with you, by being able to help the customer achieve real value out of your product.
The nature of engagement could depend on the stage the customer is in the relationship. Is the customer in the early stage of product adoption? This could then point to the fact that the customer is unable to get set up with your product. Here, you have to make sure that the customer has access to enough training material, maybe the customer requires additional onboarding support.
If the customer is in the middle stage, it could be that the customer is not realizing enough business value out of your product. Here, you need to check in with your customer, to see whether they are making enough progress towards their goals. If the customer is in late stage, it is possible that they are looking at competitor offerings, or they were frustrated with bugs, and hence the discussion would need to be shaped accordingly.
To tailor the nature of your conversation, you need to take a close look at the customer product interaction metrics. In our example, all the customer usage patterns, test performance, books read, word literacy, etc, were collected and presented as a dashboard, as a single point of reference for the sales and marketing team to easily review customer engagement levels, to be able to connect constructively with the customer management.
Conclusion If you are looking at reducing your customer churn and improving customer retention, it all comes down to predicting customers at risk of churn, analyzing the reasons behind churn, and then taking appropriate action. Machine learning based models are of particular help here, as they can take into account hundreds and even thousands of different factors, which may not be obvious or even possible to track for a human analyst. In this example, the SPECTRA platform helped the client sales team to predict the customers’ inclination for renewal of the specific learning product with 92% accuracy.
Nobody likes remembering credentials. They appear like exerting plenty of pressure on the memory. What is worse is many use identical username and password, no matter the application they are using. Single Sign-On (SSO) could be a method of authentication that permits websites to use other trustworthy sites to verify users. Single Sign-On allows a user to log into any independent application with one ID and password. Verification of user identity is very important when it involves knowing which permissions a user will have. OKTA is a leading IDAM application that our client uses for managing access that blends user identity management solutions with SSO solutions. SPECTRA, an analytical platform which is supported by open source technology has recently been on boarded for the client who is into publishing space. The client has integrated all their applications under one roof of IDAM (OKTA). SPECTRA also follows the same route.
What is SPECTRA? SPECTRA is a Big Data Analytics platform from Relevance Lab, which has the ability to consume, store and process structured and unstructured data. It also can cleanse and integrate this data into one unique platform. It depicts data intelligently and presents it using an intuitive visualization layer so that business users can get actionable business insights across various parameters. Coupled with an OCR engine, it also provides Google-like search capabilities across legacy unstructured and structured data.
SAML
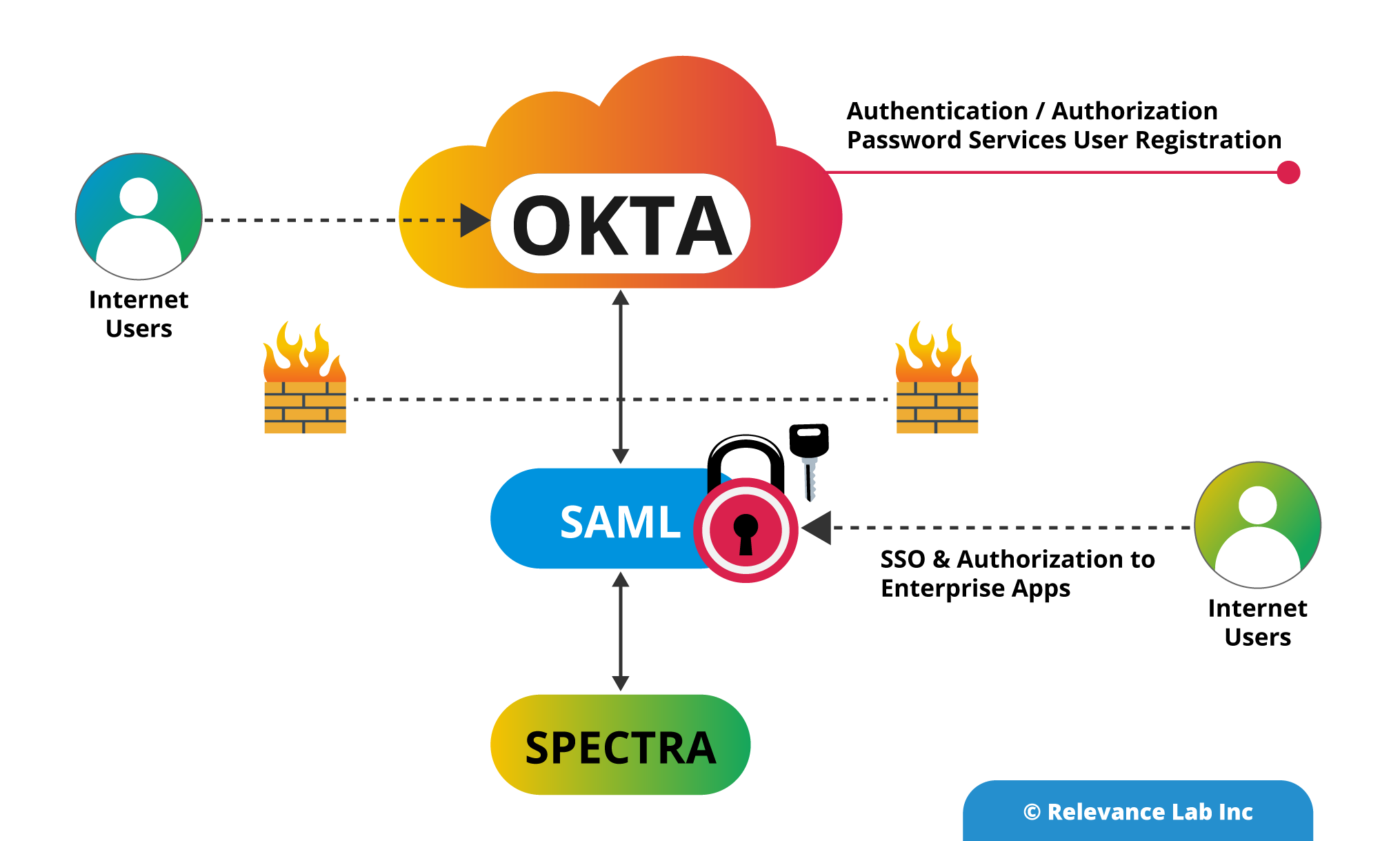
In the modern era of computing, security is an essential feature when it comes to enterprise applications. Security Assertion Markup Language (SAML) is used to provide a single point of authentication at a secure identity provider. This feature highlights that user credentials could not leave the firewall boundary. SAML is used to assert the identity to others.
SAML SSO works by transferring the user’s identity from one place (OKTA) to another service provider(SPECTRA). The application identifies the user’s origin (By First Name, Last Name & Network Email ID) and redirects the user back to the identity provider (OKTA), asking for authentication to enter the IdP registered credentials.
See the high level architectural diagram below.
Integrating with OKTA Idam Platform using SAML
Identity Provider (IdP) is an entity that provides the identities, including the flexibility to authenticate a user-agent. The Identity Provider also contains the additional user profile information like name, last name, job code, signal, address, and so on. Several service providers may require a simple user profile, while others may require a complex set of user data (job code, department, address, location, manager, etc).
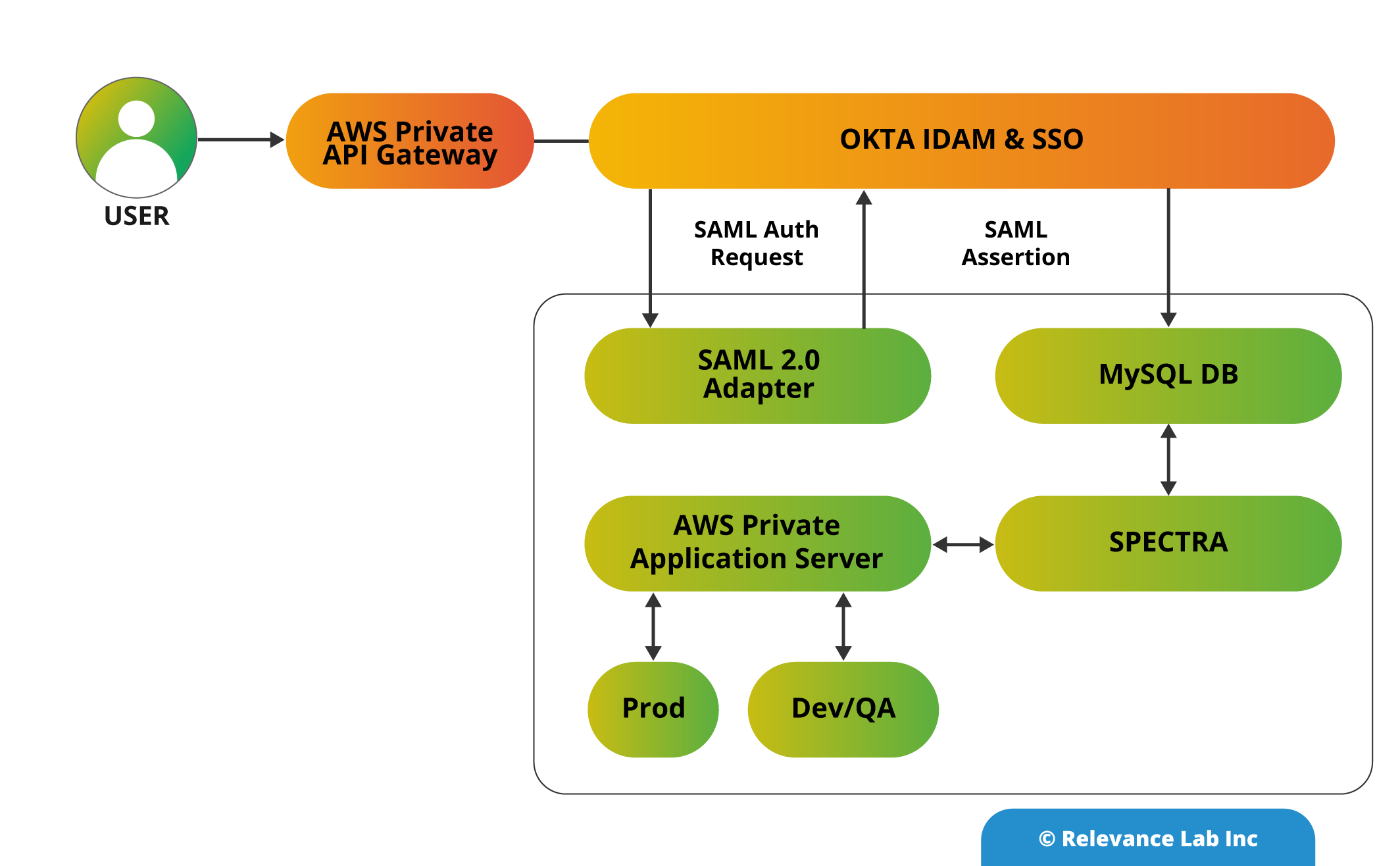
See the diagram below which show Spectra and SAML Integration.
SAML Request, also referred to as an authentication request, is generated by the SPECTRA (Service Provider) to “request” an authentication through IdP to User-Agent. SAML Response is generated by the Identity Provider. It contains the accurate assertion of the authenticated user. Additionally, a SAML Response also contains additional information, like user profile information and group/role information, betting on what the Service Provider can support.
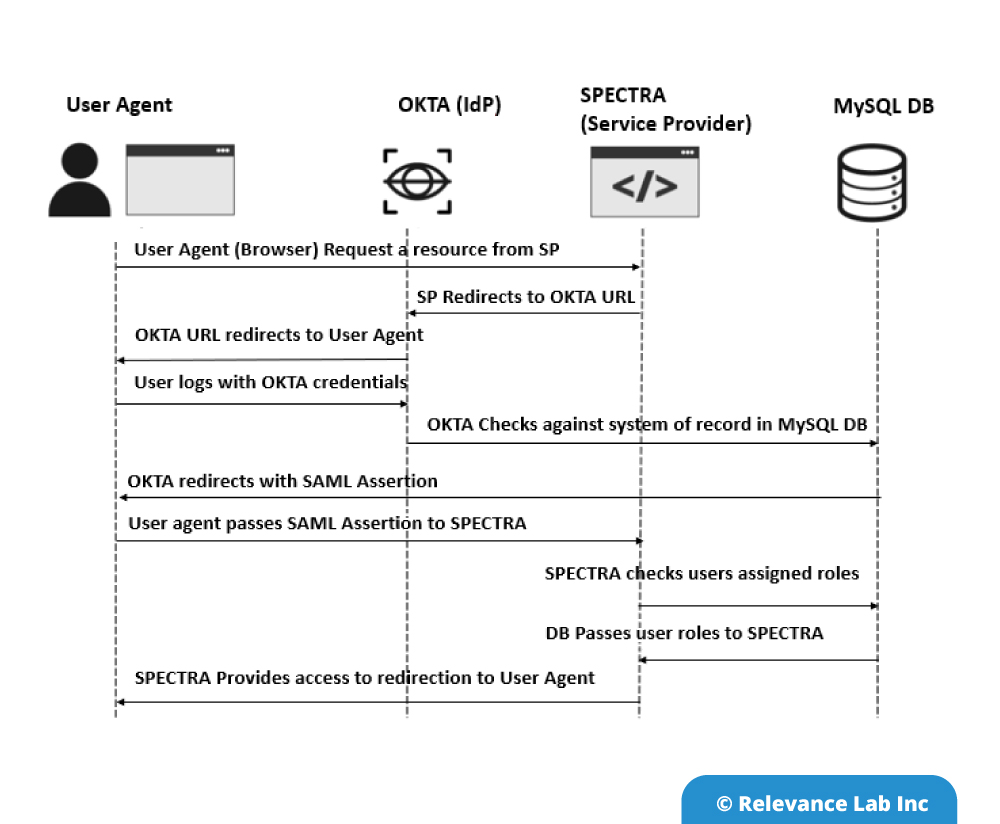
See the picture below which shows SAML Integration flow.
SPECTRA platform initiates sign-in describes the SAML sign-in flow when initiated by the Service Provider. This is triggered when the end-user tries to access a resource or log-in directly on the Service Provider side, like when the user-agent (browser) tries to access a protected resource on the Service Provider side.
An Identity Provider (Idp) initiates sign-in depicts the SAML sign-in request created by the Identity Provider. The Idp initiates a SAML Response that is redirected to the Service Provider to confirm the user’s identity, rather than the SAML flow being triggered by a redirection from the SPECTRA. The Service Provider not once directly interacts with the Identity Provider. User-Agent (browser) functions as the agent to carry out all the redirections. The Service Provider must know which Idp to pass on to the MySQL database. The Service Provider must authenticate the user until the SAML assertion comes back from the Idp.
An Identity Provider can initiate an authentication flow. The SAML authentication flow is asynchronous. The Service Provider interacts with Idp and redirects the request to the complete flow. This creates a situation where the Service Provider will not maintain any state of authentication requests. The response that Service Provider gets from an Identity Provider must contain all the required information. SPECTRA validate the OKTA user information in MySQL DB and transfer the assigned user roles in the application. User can view the assigned roles within the application.
SPECTRA, a product from Relevance Lab offers great flexibility as an analytical platform that has ability to consume, store and process structured and unstructured data. It can be integrated with various Identity Access Management platforms like OneLogin, AuthO, Ping Identity, etc using SAML.
Modern scientific research depends heavily on processing massive amounts of data which requires elastic, scalable, easy-to-use, and cost-effective computing resources. AWS Cloud provides such resources, but researchers still find it hard to navigate the AWS console. RLCatalyst Research Gateway simplifies access to HPC clusters using a self-service portal that takes care of all the nuts and bolts to provision an elastic cluster based on AWS ParallelCluster 3.0 within minutes. Researchers can leverage this for their scientific computing.
Relevance Lab has been collaborating with AWS Partnership teams over the last one year to simplify access to High Performance Computing across different fields like Genomics Analysis, Computational Fluid Dynamics, Molecular Biology, Earth Sciences, etc.
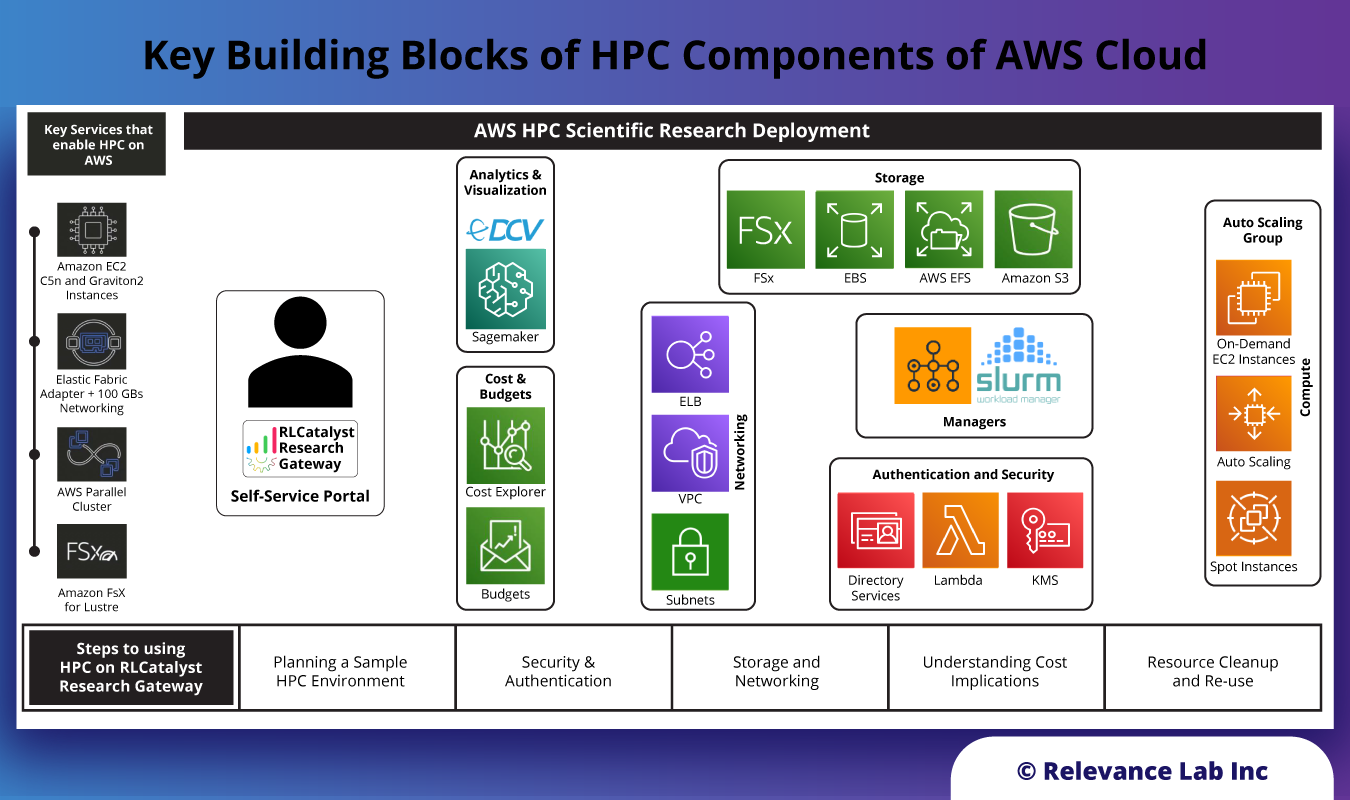
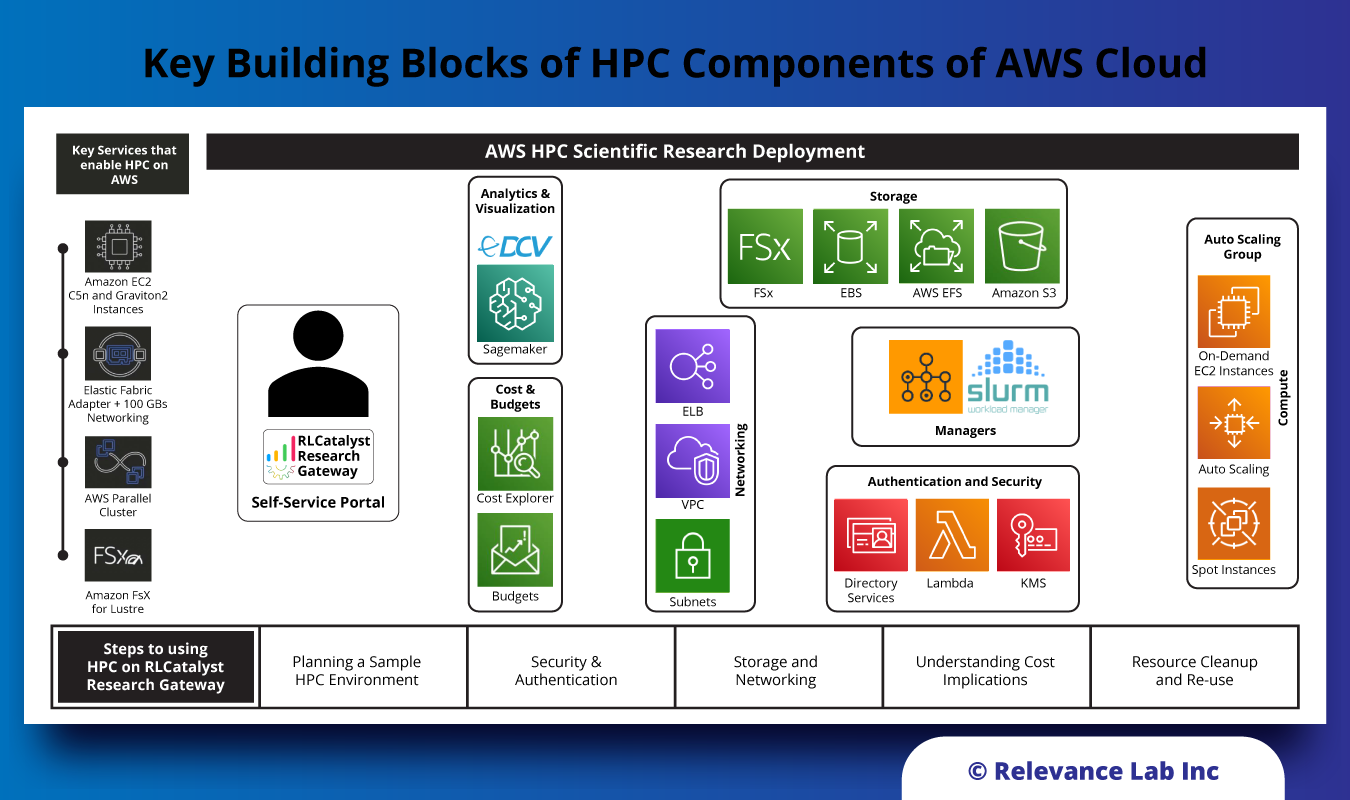
There is a growing need from customers to adopt the High Performance Computing capabilities in the public cloud. However this throws in key challenges related to right architecture, workload migration and cost management. Working closely with AWS HPC groups we have been enabling adoption of AWS HPC solutions with early adopters in Genomics and Fluid Dynamics with Higher Education and Healthcare customers. The primary ask is for a self-service Portal for planning, deploying and managing HPC workloads with security, cost management and automation. The figure below shows the key building blocks of HPC Architecture part of our solution.
AWS ParallelCluster 3.0
AWS ParallelCluster is an open source cluster management tool written using Python and is available via the standard python package index (PyPI). Version 3.0 also provides support for APIs and Research Gateway leverages this to integrate with the AWS Cloud to set up and use the HPC cluster for complex computational tasks. AWS ParallelCluster supports two different orchestrators, AWS Batch and Slurm, which cover a vast majority of the requirements in the field. ParallelCluster brings many benefits including easy scalability, manageability of clusters, and seamless migration to the cloud from on-premise HPC workloads.
FSx for Lustre
Amazon FSx for Lustre provides fully managed shared storage with the scalability and performance of the popular Lustre file system. This storage can be accessed with very low (sub-millisecond) latencies by the worker nodes in the HPC cluster and provides very high throughput.
NICE DCV
NICE DCV is a high performance remote display protocol used to deliver remote desktops and application streaming from resources in the cloud to any device. Users can leverage this for their visualization requirements.
Research Gateway Provides a Self-Service Portal for AWS PCluster 3.0 Launch with Automatic Cost Tracking
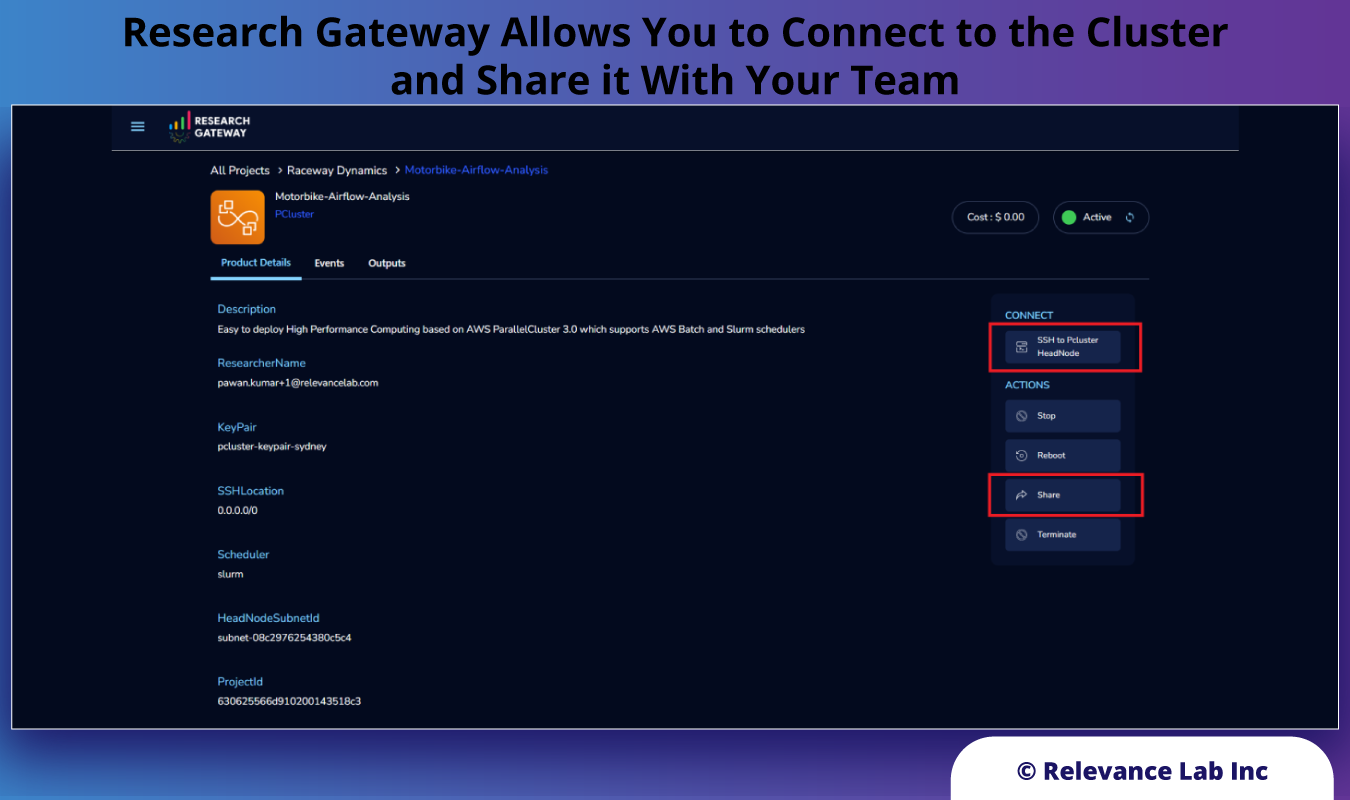
Using RLCatalyst Research Gateway, research teams are organized into projects with their own catalog of self-service workspaces that researchers can provision easily with minimum knowledge of AWS cloud setup. The standard catalog, included with RLCatalyst Research Gateway, now has a new item called PCluster which a Principal Investigator can add to the project catalog to make it available to their team. This product is based on AWS ParallelCluster 3.0 which is a command line tool that advanced users can work with. Research Gateway has wrapped this tool with an intuitive user interface.
To see how you can set up an HPC cluster within minutes, check this video.
The figure below shows a standard catalog inside Research Gateway for users to provision PCluster and FSx for Lustre with ease.
Setting Up a Shared Cluster for Use in the Project
The PCluster product on Research Gateway offers a lot of flexibility. While researchers can set up and use their own clusters, sometimes there is a need to use a shared cluster across collaborators within the same project. Towards this goal, we have also brought in a feature that allows a user to “share” the cluster with the entire project team. The other users can then connect to the same cluster and submit jobs. For example a Principal Investigator might set up the cluster and share it with the researchers in the project to use for their computations.
Large Datasets Storage and Access to Open Datasets
AWS cloud is leveraged to deal with the needs of large datasets for storage, processing, and analytics using the following key products.
Amazon S3 for high-throughput data ingestion, cost-effective storage options, secure access, and efficient searching.
AWS Datasync for secure, online service that automates and accelerates moving data between on-premises and AWS storage services.
AWS Open Datasets program houses openly available, with 200+ open data repositories.
Cost Analysis of Jobs
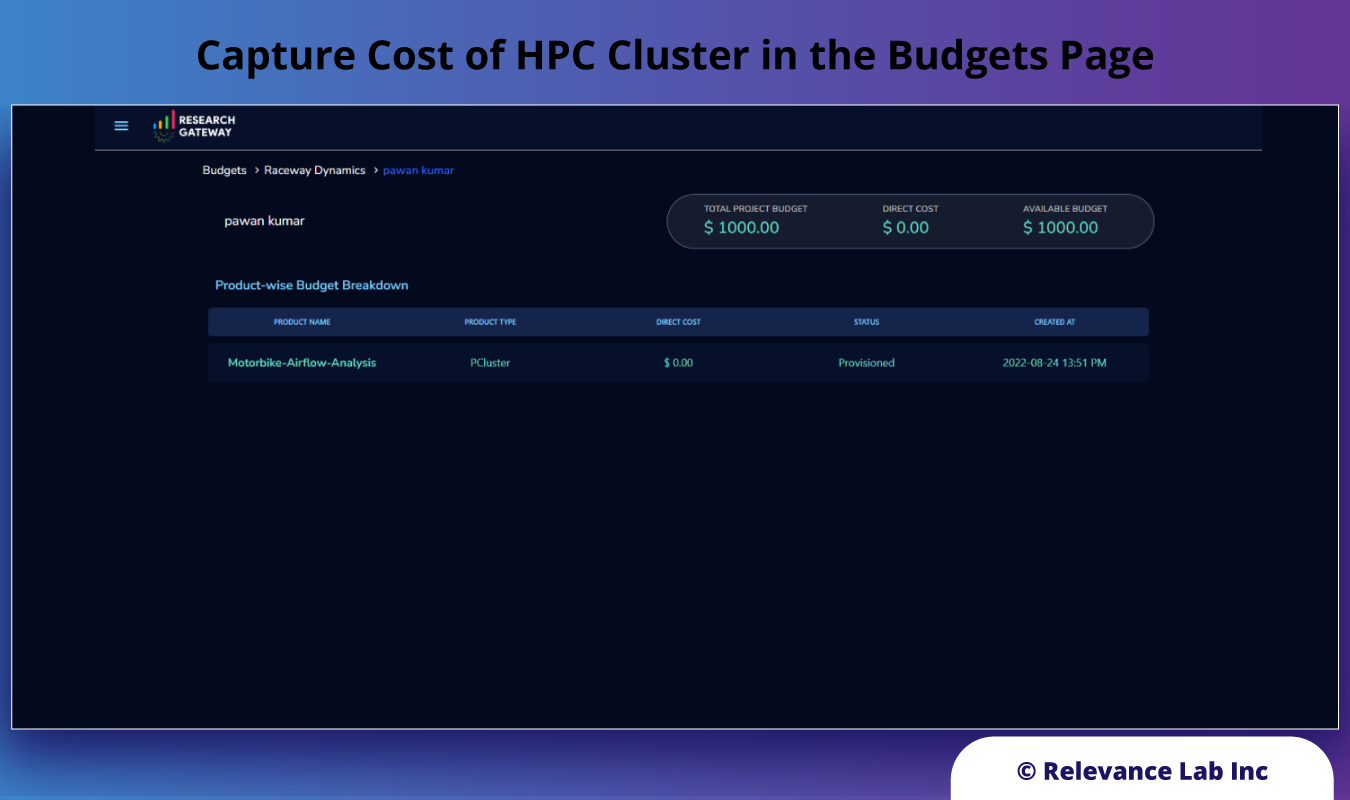
Research Gateway injects cost allocation tags into the ParallelCluster so that all resources created are tagged and the cost of the scalable cluster can easily be monitored from the Research Gateway UI.
Summary
AWS Cloud provides services like AWS ParallelCluster and FSx for Lustre that can help users with High Performance Computing for their scientific computing needs. Research Gateway makes it easy to provision these services with a 1-Click, self-service model and provides cost and governance to help manage your budget.
As digital adoption grows, so do user expectations for always-on and reliable business services. Any downtime or service degradation can have serious impacts on the reputation of the company and its business with brutal reviews and poor customer satisfaction. The classic pursuit of DevOps helps businesses deliver new digital experiences faster, while Site Reliability Engineering (SRE) ensures the promises of better services actually stay consistent beyond the launch. Relevance Lab is helping customers take DevOps maturity to the next level with successful SRE adoptions and on the path to AIOps implementations.
Relevance Lab has been working with 50+ customers on the adoption of cloud, DevOps, and automation over the last decade. In the last few years, the interest in AIOps and SRE has grown, especially among large and complex hybrid enterprises. These companies have speeded up the journey to cloud adoption and techniques of DevOps + Automation across the products lifecycle. At the same time, there is confusion among these enterprises regarding taking their maturity to the next level of AIOps adoption with SRE.
Working closely with our existing customers and with best practices built as part of the journey, we present a framework for SRE adoption of large and complex enterprises by leveraging a unique approach from Relevance Lab. It’s built on the concept of RLCatalyst as a platform for SRE adoption that is faster, cheaper, and more consistent.
The basic questions we have heard from our customers looking at adopting SRE are the following:
We want to adopt the SRE best practices similar to Google, but our context of business, applications, and infrastructure is very diverse and needs to consider the legacy systems.
A number of applications in our organization are business applications that are very different from digital applications but need to be part of the overall SRE maturity.
The cloud adoption for our enterprise is a multi-year program, so we need a model that helps adopt SRE in an iterative manner.
The CIO landscape for global enterprises covers different continents, regions, business units (BU), countries, and products in a diverse play covering 200+ applications, and SRE needs to be a framework that is prescriptive but flexible for adoption.
The organizational structure for large enterprises is complex, with different specialized teams and specialist vendors helping manage operations across Infrastructure, Applications Support, and Service Delivery that was built for an era of on-premise systems but is not agile.
Different groups have tried a movement toward SRE adoption but lack a consistent blueprint and partner who can advise, build, and transform.
The reflection of lack of SRE presents on a daily basis with a long time for critical incident handling, issues tossing between groups, repetitive poor outcomes, and excessing focus on process compliance without end-user impacts.
The basic concepts covered in the blog are the following and are intended to act as a handbook for new enterprises in the adoption of the SRE framework:
What is the definition and the scope of SRE for an enterprise?
Is there a framework that can be used to adopt SRE for a large and complex hybrid enterprise?
How can Relevance Lab help in the adoption and maturity of SRE for a new enterprise?
What is unique about Relevance Lab solutions leveraging a combination of Platform + Services?
What is SRE?
SRE refers to Site Reliability Engineering. It is responsible for all the critical business services. It ensures that end customers can rely on IT for their mission-critical business services. Site Reliability Engineers (SREs) ensure the availability of these services, building the tools and automation to monitor and enable this availability. A successful SRE implementation also requires the right organizational structure along with tools and technologies.
SRE Building Blocks/Hierarchy of Reliability
Relevance Lab’s SRE Framework consists of 5 building blocks, as shown in the following image.
As shown above, the SRE building block consists of an Initial Assessment, Monitoring and Alerting Optimization, Incident handling with self-heal capability, Incident Prevention, and an end-to-end SRE dashboard.
RL SRE Framework
Relevance Lab’s SRE framework provides a unique approach of Platform + Competencies for multiple global enterprises. RL’s SRE adoption presents a unique way of solving the problems related to critical business applications availability, performance, and capacity optimization. The primary focus is on ensuring critical business services are available while all issues are proactively addressed. SRE also needs to ensure an automation-led operations model delivers better performance, quality, and reliability.
Our methodology for SRE Implementation consists of the following:
The initial step for any application group or family is to understand the current state of maturity. This is done by assessment checklist, and the outcome of this would decide if the application would qualify for SRE implementation. In case the application doesn’t qualify for SRE implementation, the next step would be to fix the basic requirements that need to be in place for effective SRE implementation. The same would be reassessed post putting the basic check in place.
Based on the assessment activity and the gaps identified, we will recommend the steps that need to be in place for an effective SRE model. The outcome of the assessment would translate into an Implementation Plan. Below are the 5 Steps required to implement SRE for an Organization:
Level 1: Monitoring – Focuses on 4 Golden Signals, Service Level Agreements (SLA) and Service Level Objectives (SLO)/Service Level Indicator (SLI), and Error Budgets
Our Uniqueness
Relevance Lab’s SRE framework for any cloud or hybrid organization goes through Enablement Phase and Maturity Phase. In each phase, there are platform-related activities and application-related activities. Every application goes through a Phase 1 Enablement journey to reach stabilization and then move towards Phase 2 Maturity.
Phase 1 – Enablement is a basic SRE model that helps enterprise reach a basic level of SRE implementation, and this covers the first 3 stages of the Relevance Lab SRE Framework. This will include the implementation of new tools, processes, and platforms. At the end of this phase, a clear definition of the golden signals, SLI/SLOs against SLA, and Error Budgets are defined, monitored, and tracked. The refined runbooks and operating guides help in the proactive identification of Incidents and faster recovery due to on-call management. Activities like Post Incident Review, Pressure Tests, Load testing, etc., help stabilize the application and the infrastructure. As part of this phase, an SRE 1.0 dashboard is available as an output to monitor the SRE metrics.
Phase 2 – Maturity is an advanced SRE model which covers the last two stages of the Relevance Lab SRE Framework. It emphasizes on automation-first approach for an end-to-end lifecycle management, and includes advanced release management, auto-remediations for Incident management, security, and capacity management. This will be an ongoing maturity phase to bring in additional applications and BUs under the scope of the SRE model. The output of this phase will be an automated SRE 2.0 dashboard, which will have intelligence-based actionable insights & prevention.
Summary
Relevance Lab (RL) has worked with multiple large companies on the “Right Way” to adopt Cloud and SRE maturity models. We realize that each large enterprise has a different context-culture-constraint model covering organization structures, team skills/maturity, technology, and processes. Hence the right model for any organization will have to be created as a collaborative model, where RL will act as an advisor to Plan, Build and Run the SRE model based on the framework (RLCatalyst) they have created.
For more information on RL’s SRE framework and maturity model or for its implementation, feel free to contact marketing@relevancelab.com
While there are a lot of talks about Digital Innovation leveraging the cloud, another key disruption in the industry is Applied Science Innovation, led by Scientists and Engineers targeting a broad range of disciplines in Engineering and Medicine. Relevance Lab is proud to now ease the leverage of power tools like High-Performance Computing (HPC) and Quantum Computing on AWS Cloud for such pursuits with our Research Gateway product.
What is Applied Science?
Applied Science uses existing scientific knowledge to solve day-to-day problems in areas like Health Care, Space, Environment, Transportation, etc. It leverages the power of new technologies such as Big Compute and Cloud to drive faster scientific research. Innovation in Applied Science has some unique differences compared to Digital Innovation:
Users of Applied Science are researchers, scientists, and engineers
Workloads for Applied Science are driven by more specialized systems and domain-specific algorithms & orchestration needs
Very large domain-specific data sets and collaboration with a large ecosystem of global communities is a key enabler with a focus on open-source and knowledge sharing
Use of specialized hardware and software is also a key enabler
The term Big Compute is used to describe large-scale workloads that require multiple cores (with specialized CPU and GPU types) working with very high-speed network and storage architectures. Such Big Compute architectures solve the problems in image processing, fluid dynamics, financial risk modeling, oil exploration, drug design, etc.
Relevance Lab is working closely with AWS in pursuing specialized use cases for Applied Science and Scientific Research using Cloud. A number of government, public and private sector organizations are focussing large amounts of investment and scientific knowledge on driving innovation in these areas. A few specialized ones with well-known programs are listed below.
What is High Performance Computing?
Supercomputers of the past were very specialized and high-cost systems that could only be built and afforded by large and well-funded institutions. Cloud computing is driving the democratization of supercomputers by providing High Performance Computing (HPC) systems that have specialized architectures. It combines the power of on-demand computing with large & specialized CPU/GPU types, high-speed networking, fast access storage, and associated tools & utilities for workload orchestration and management. The figure below shows the key building blocks of HPC components of AWS Cloud.
What is Quantum Computing?
Quantum computing relies upon quantum theory, which deals with physical phenomena at the nano-scale. One of the most important aspects of quantum computing is the quantum bit (Qubit), a unit of quantum information that exists in two states (horizontal and vertical polarization) at the same time, thanks to the superposition principle of quantum physics.
What Do Customers Want?
The availability of specialized services like HPC and Quantum Computing has made it extremely simple for customers to be able to consume these advanced technologies and build their own supercomputers. However, when it comes to the adoption cycle, customers are hesitant to adopt the same due to key concerns and asks, as summarized below:
Operational Asks:
The top challenge and fear on the cloud is the variable cost model, which can throw a big surprise, and customers want strong Cost Management & Tracking with auto-limits control
Security and data governance are also key priorities
Data transfer and management are the other key needs
Functional Asks:
Faster and easier design, provisioning, and development cycles
Integrated and automated tools for deployment and monitoring
Easy access to data and the ability to do self-service
Derive increased business value from Data Analytics and Machine Learning
How Does Research Gateway Solve Customer Needs?
AWS cloud offerings provide a strong platform for HPC and quantum computing requirements. However, enabling Scientific Research and Training of Researchers requires an ability to offer these with a Self-Service Portal that encapsulates the underlying complexity. On top of proper cost tracking and controlling, security, data management, and an integrated workbench are needed for a collaborative research environment.
To address the above needs, Relevance Lab has developed Research Gateway. It helps scientists accelerate their research on the AWS cloud with access to research tools, data sets, processing pipelines, and analytics workbenches in a frictionless manner. The solution also addresses the need for tight control on a budget, data security, privacy, and regulatory compliances, which it meets while significantly simplifying the process of running complex scientific research workloads.
Research Gateway meets the following key dimensions of collaborative and secure scientific research:
Cost and Budget Governance: The solution offers easy control over Cost Tracking of Research Cloud resources to track, analyze, control, and optimize budget spending. Principal Investigators can also pause or stop the budget if it exceeds the set threshold.
Research Data & Tools for Easy Collaboration: Research Gateway provides the team of researchers real-time view of research-specific product catalog, cost, and governance, reducing the complexities of running scientific research on the cloud.
Security and Compliance: Principal investigators have a unified view and control over security and compliance, covering Identity management, data privacy, audit trails, encryption, and access management.
Principal investigators leading the research get a quick insight into the total budget, consumed budget, and available budget, along with the available research-specific products, as shown in the image below.
With Research Gateway, researchers can provision available research-specific products for their high-performance and quantum computing needs in just 1-click, launching scientific research as quickly as 30 minutes or less.
Summary
High Performance Computing and Quantum computing are essential to the advancement of science and engineering now more than ever. Research Gateway provides fundamental building blocks for Applied Science and Scientific Research in the AWS cloud by simplifying the availability of HPC and Quantum computing for customers. The solution helps create democratized supercomputers on-demand while eliminating the pain of managing infrastructure, data, security, and costs, enabling researchers to focus on science.
To know more about how you can high-performance and quantum computing with just 1-click and launch your research in 30 minutes using our solution at https://research.rlcatalyst.com, feel free to contact marketing@relevancelab.com
We use cookies on our website to provide you with a more relevant experience. To learn more about how we use cookies and how you can manage your cookie settings, please refer to our Privacy.
We do not collect and sell your personal information.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You can opt-out of non- necessary cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.