2022 Blogs, Blog, Cloud Blog, Featured
Cloud is no longer a “good-to-have” technology but rather a must-have for enterprises. Although cloud-led digital transformation has been a buzzword for years, enterprises had their own pace of cloud adoption. However, the pandemic necessitated the acceleration of cloud adoption. Enterprises are faced with a new normal of operation that requires the speed and agility of the cloud.
In this blog, we will discuss the ground realities and challenges. We will also explore how Relevance Lab (RL) offers the right mix of experience and proven approaches to grow in today’s hyper-agile industry environment.
A Changed Ground Reality
Pandemic has accelerated how organizations look at IT infrastructure spending. It has also permanently changed their cloud strategies & spending habits. Online reports suggest that 38% more companies took a cloud-first approach compared to 2020 with an increased focus on IaaS and PaaS-based approaches.
According to a Gartner online survey, enterprises have preponed their cloud adoption by several years and this is expected to continue in the near future. The survey also predicts that enterprises will spend more on a just-in-time, value-based adoption to match the demands of a hyper-competitive environment.
Migration and modernization with the cloud is a long-term trend, especially for enterprises with a need to scale up. As CAPEX takes a back seat, OPEX is now at the forefront. Cloud as an industry has matured and evolved over a period of time, enabling faster and better adoption with hyper accelerator tools.
Criteria for the Successful Cloud Journey
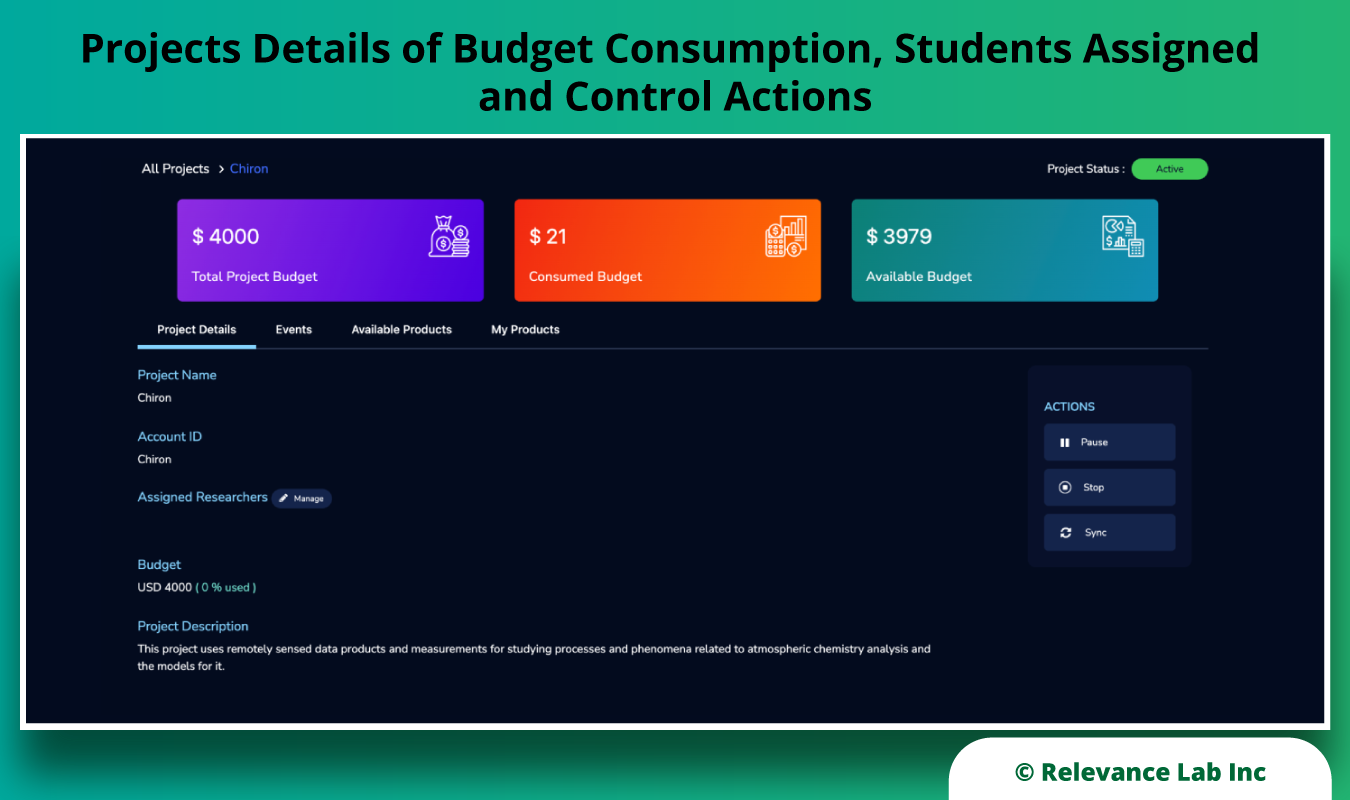
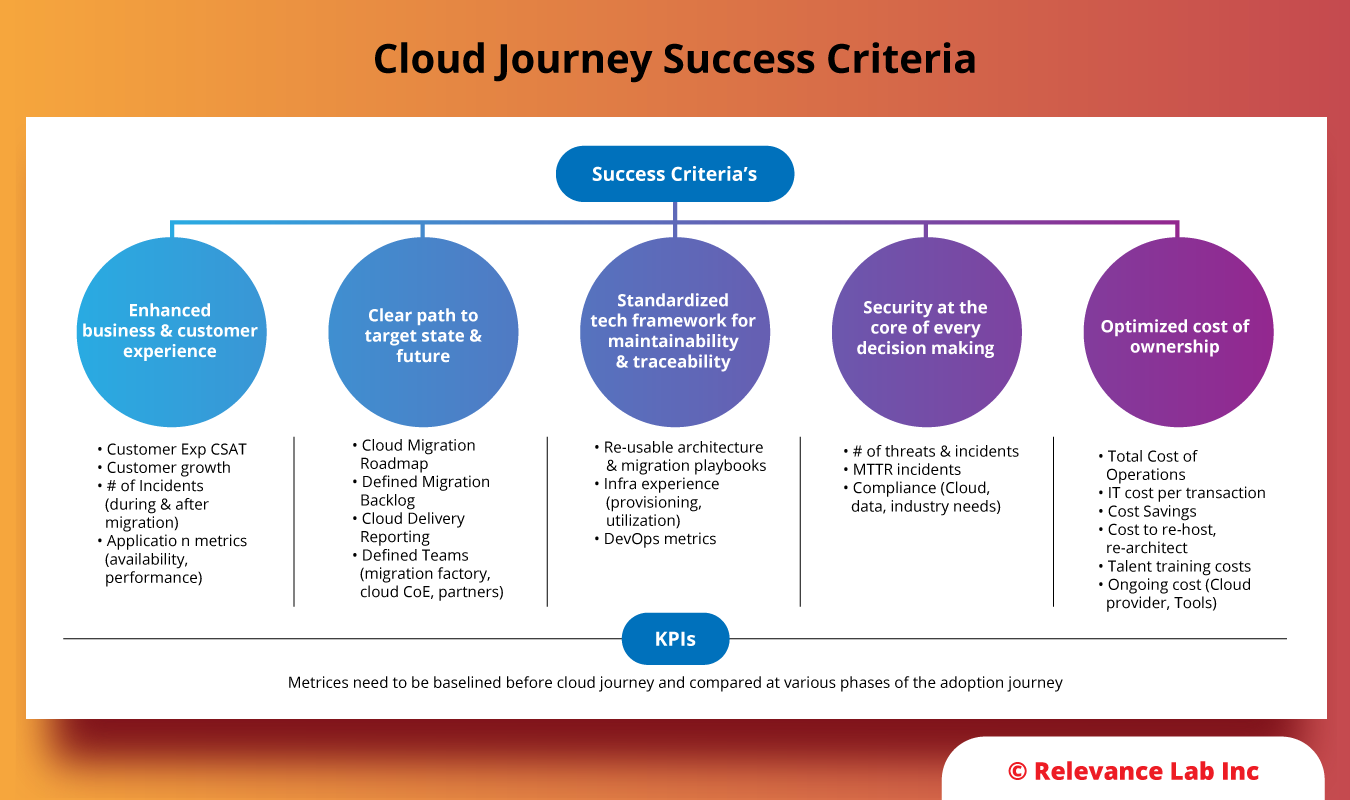
The success of an enterprise’s cloud adoption journey can be evaluated by setting and measuring against the right KPIs. A successful cloud journey would help an enterprise achieve “business as usual” along with enhanced business outcomes and customer experience. It standardizes the framework for maintainability and traceability, improves security, and optimizes the cost of ownership, as shown in the image below.
Common Cloud Migration Challenges
Planning for and meeting all the criteria of a successful cloud journey has always been an uphill task. Some of the common challenges are:
Large Datasets: Businesses today are dealing with larger and more unstructured datasets than ever before.
Selection of Right Migration Model: Many enterprises, starting their cloud journey, have to choose the right migration model for adoption as per their needs, such as legacy re-write, lift & shift, and everything in between. The decision is based on various different factors like cost, business outlook, etc, and can impact business performance and operations in the longer run.
Change Management for Adopting a New Way of Operation: Cloud migration requires businesses to expand their knowledge at a rapid rate along with real-time analytics & personalization.
Security Framework: The risk of hackers & security attacks is growing across most industries. To keep up with the security while successfully moving to the cloud, enterprises need robust planning and an action list. Also, enterprises must choose a security framework depending on their size, industry, compliance, and governance needs.
Lack of Proper Planning: Rushed application assessments give rise to a lot of gaps that can affect the cloud environment. As a move into the cloud impacts different verticals and businesses as a whole, all stakeholders must be on the same page when it comes to an adoption plan.
Profound Knowledge: Cloud migration requires a dedicated and experienced team to troubleshoot any problems. While building an in-house team is a time-consuming, costly and tumultuous task, working with partners with knowledge branching into different technologies may not be a beneficial idea as well. Enterprises may need a partner with a focused understanding of the cloud migration niche as they will have assimilated knowledge from their engagement with various customers.
Continuous Effort: Cloud is ever-changing with new developments and evolving paradigms. Thus, cloud migration is not a one-time task but rather requires continuous effort to automate and innovate accordingly.
Solutions to Cloud Migration Challenges
Some of the potential solutions that an enterprise can adopt to overcome common challenges of cloud migration are:
- Reassessing cloud business & IT plans
- Identify and remediate risks and gaps in data, compliance, and tech stack
- Detailed migration approaches with self-sufficient virtual ecosystems
- Helps build, deliver and fail fast
- Data-driven analysis enables stakeholders to make quick and effective decisions
Planning the solutions requires extensive experience and knowledge to implement. They can reap the benefits of the cloud easily with the combination of the right approach and solution.
How Relevance Lab Helps Businesses Accelerate their Cloud Journey
Relevance Lab (RL) is a specialist company in helping customers adopt cloud “The Right Way”. It covers the full lifecycle of migration, governance, security, monitoring, ITSM integration, app modernization, and DevOps maturity. We leverage a combination of services and products for cloud adoption. Helping customers on a “Plan-Build-Run” transformation, we drive greater velocity of product innovation, global deployment scale, and cost optimization.
Building Mature Cloud Journey
Moving to the cloud opens up numerous opportunities for enterprises. To reap all the benefits of cloud migration, enterprises need a comprehensive strategy focused on building value, speed, resilience, scalability, and agility to optimize business outcomes. Having worked with businesses across the globe for over a decade, our teams have seen a common trend that enterprises are often unaware of unprecedented adoption challenges, the “day-after” surprises and complexities, or the chronology of their occurrence.
This begs the question – how enterprises can overcome such surprises? Relevance Lab helps you answer it with a comprehensive and integrated approach. Combining cloud expertise and experience, we help enterprises overcome any challenge or surprise coming their way. Meeting the current needs of the clients, we help you build a cohesive and well-structured journey. Here are a few ways Relevance Lab helps you achieve it:
1. Assess the Current State & Maturity of the Cloud Journey
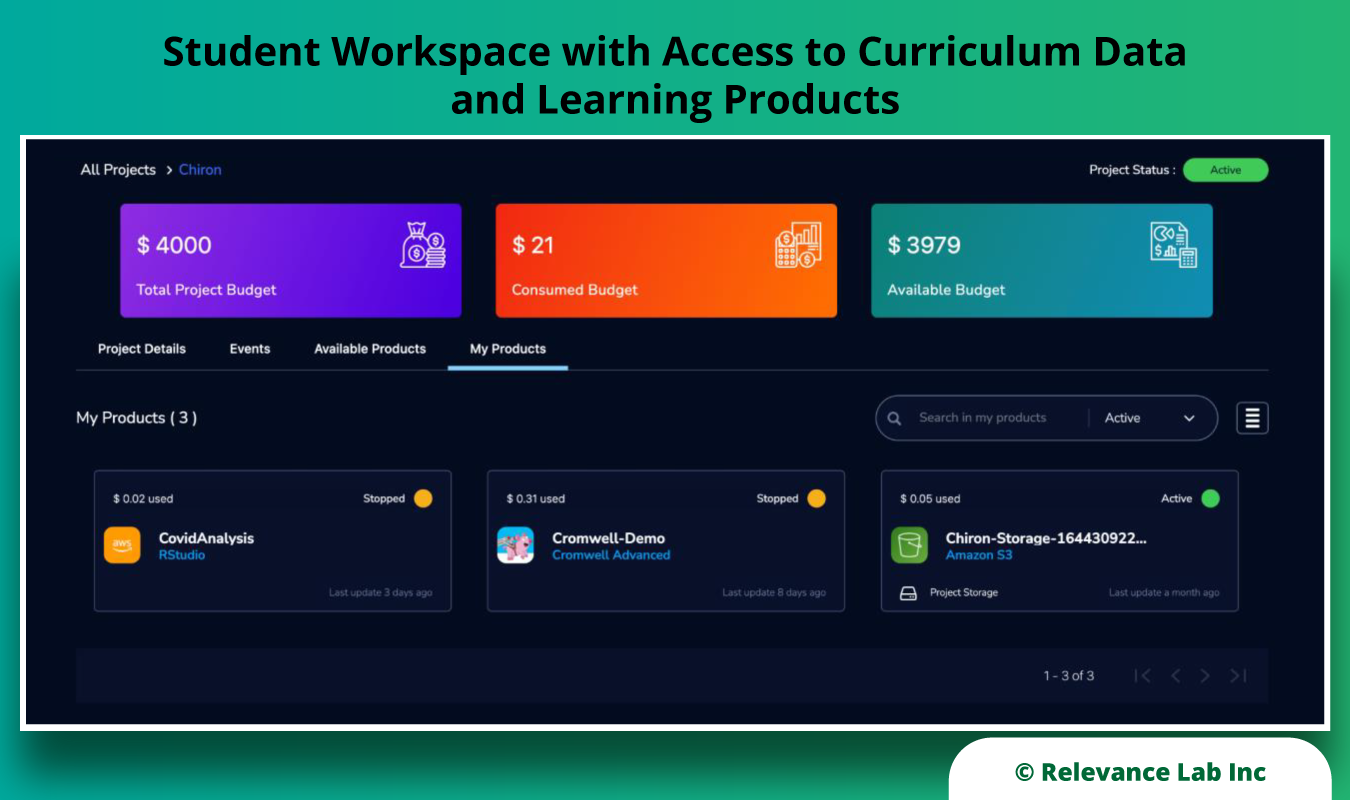
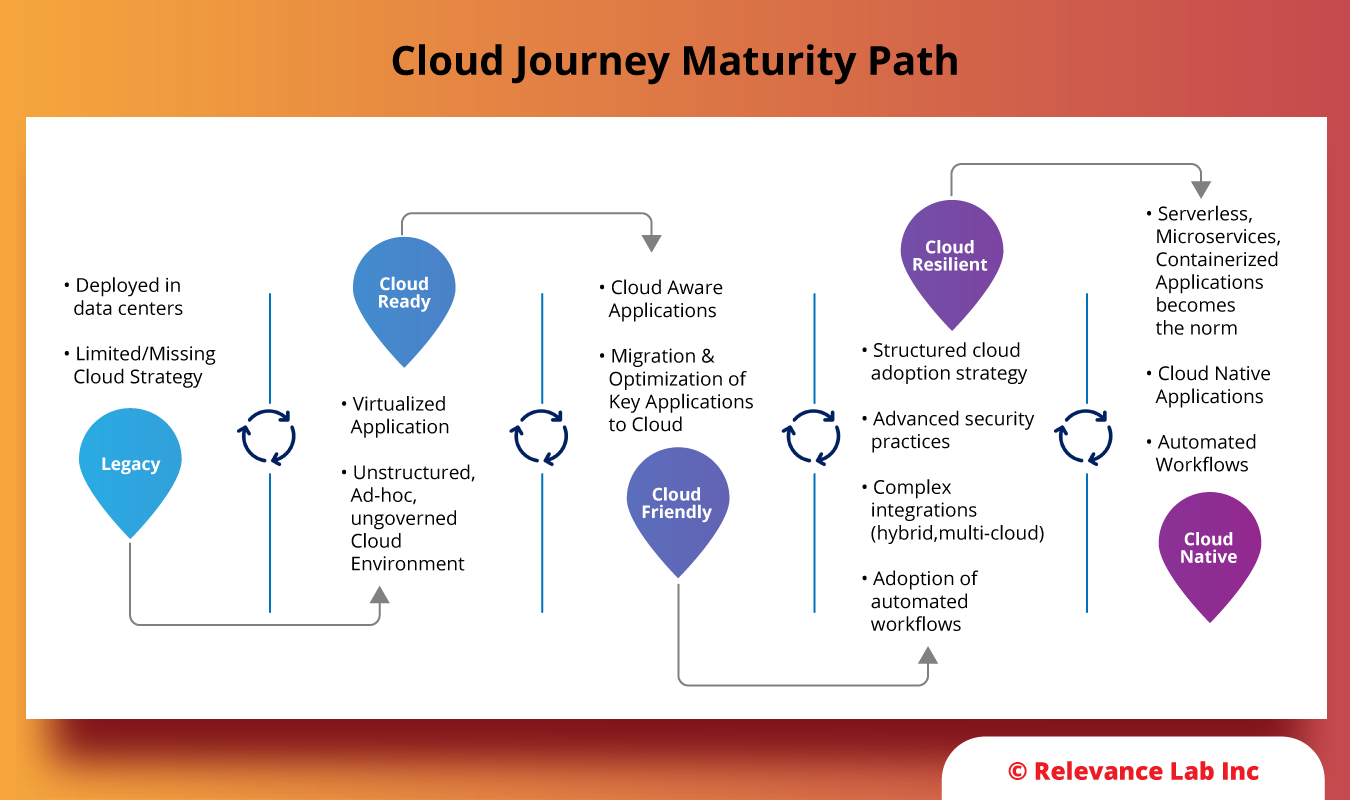
Any enterprise must get a clear picture of its current state before they build a cloud strategy. At Relevance Lab, we help clients assess their structures and requirements to identify their current stage on the cloud maturity journey. The cloud maturity model has 5 stages, namely, Legacy, Cloud Ready, Cloud Friendly, Cloud Resilient, and Cloud Native, as shown in the image below. This helps us to adopt the right approach that matches the exact needs of our clients.
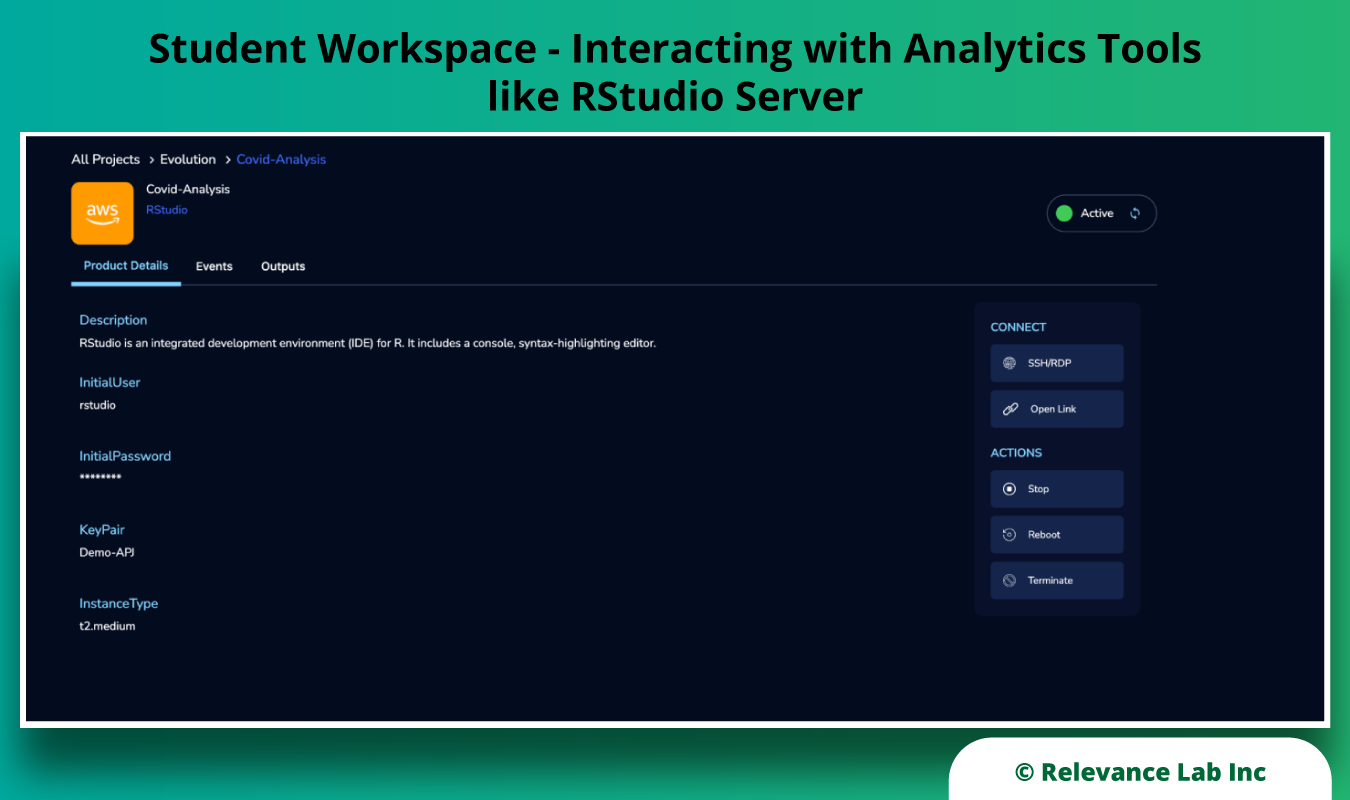
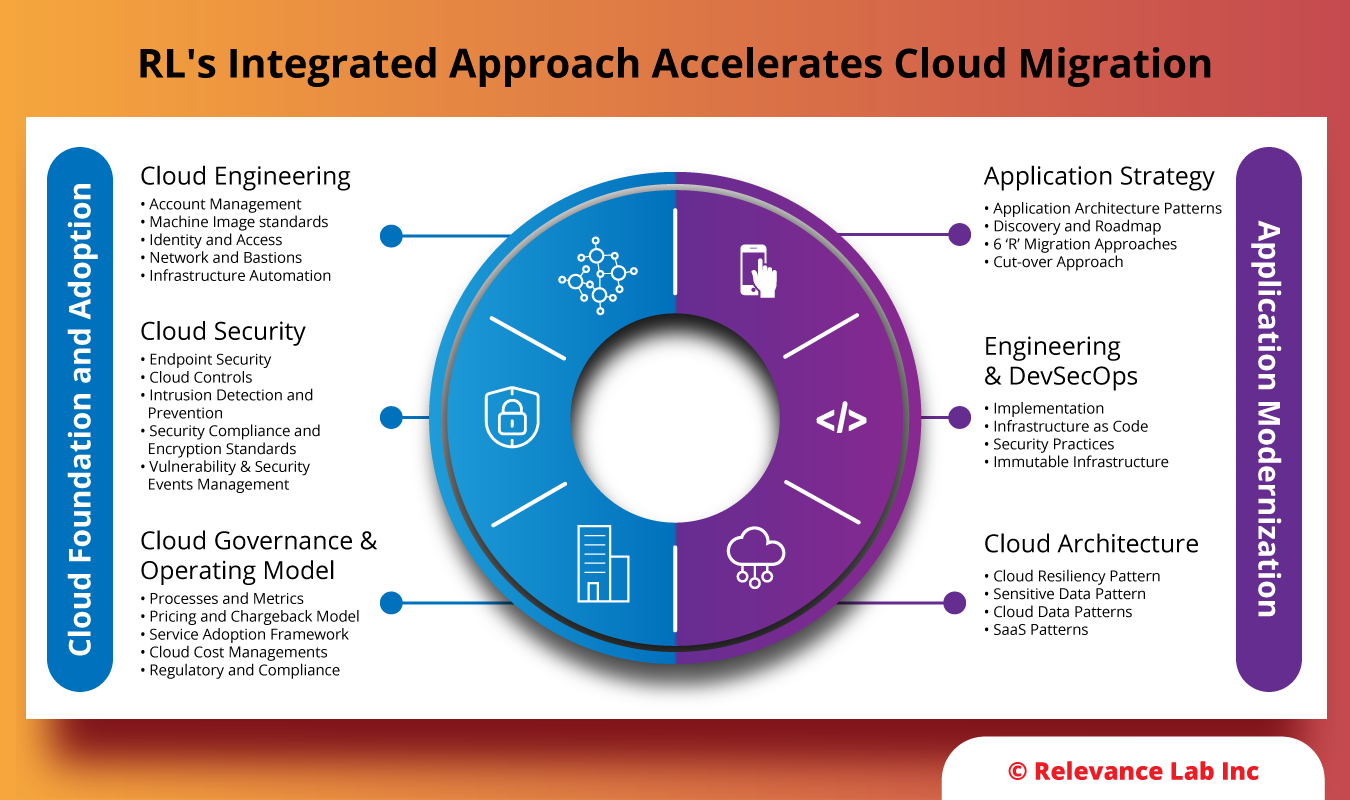
Once the current stage is determined after an assessment, RL helps in designing an effective cloud strategy with a comprehensive and integrated approach keeping a balance between cloud adoption and application modernization. We ensure that all elements of cloud adoption move together, i.e, cloud engineering, cloud security, cloud governance & operating model, application strategy, engineering & DevSecOps, and Cloud Architecture, as shown in the image below.
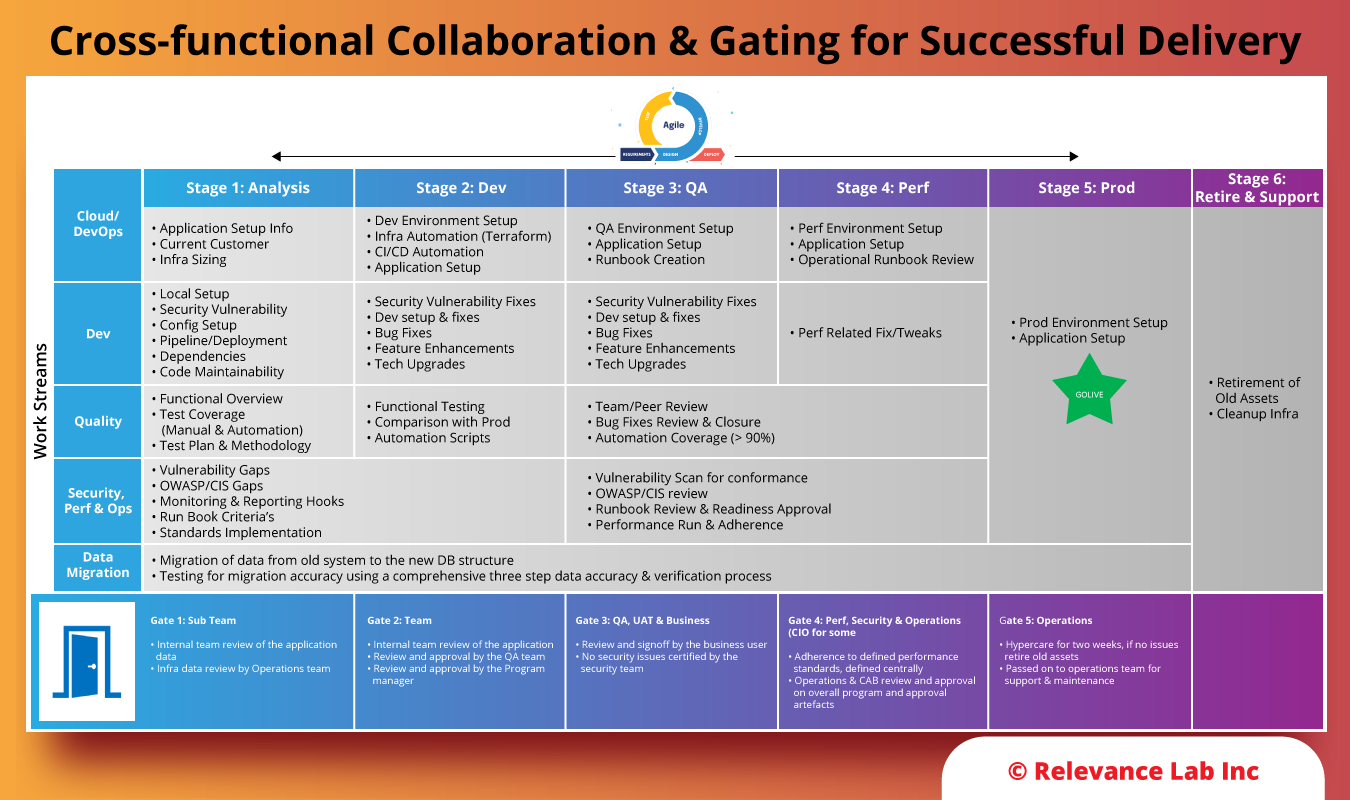
2. Execute & Deliver through a Cross-Functional Collaboration and Gating Process
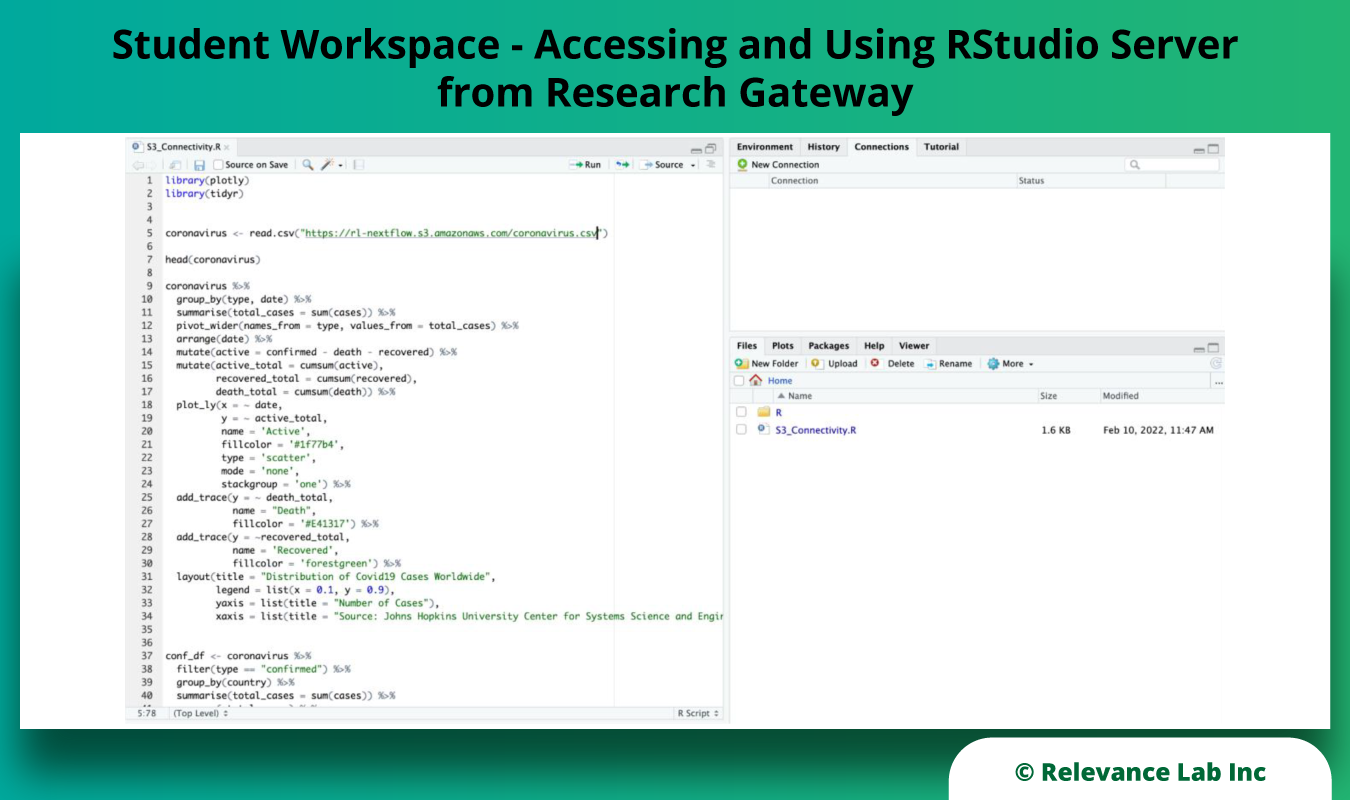
After the approach is defined and the strategy is designed, workstreams that integrate people, tools, and processes are identified. Cloud adoption excellence is delivered through cross-functional collaboration and gating across workstreams and stages, as shown in the image below.
How We Helped a Publishing Major Migrate “The Right Way”
Let’s explore a detailed account of how we implemented them for a global publishing major to maximize cloud benefits.
The publishing major was heavily reliant on complex legacy applications and outdated tech stack resulting in security & legal liabilities. There was a pressing need to scale IT and Product engineering to meet market demands driven by usage uptick (triggered by pandemic). Another immediate requirement was the need for better data gathering & analytics to enable faster decision making.
Relevance Lab provided an enterprise cloud migration solution with a data-driven plan and collaboration with business stakeholders. A comprehensive framework prioritizing customer-centric applications for scale and security was put in place. RL helped in implementing an integrated approach leveraging cloud-first and secure engineering & deployment practices along with automation to accelerate development, deployment, testing & operations.
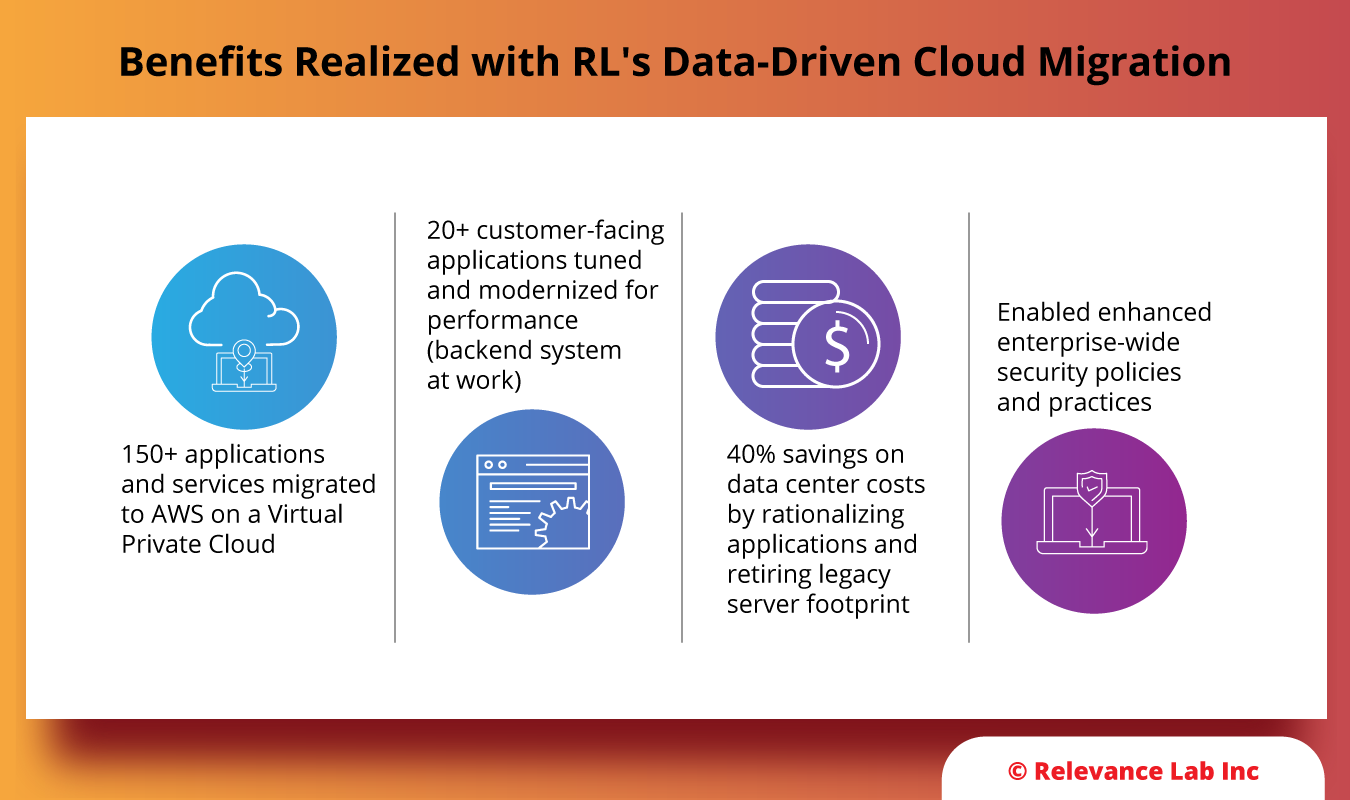
To further learn about the details of how RL helped the above global publishing giant, download our case study.
Conclusion
Given the current times, cloud adoption strategy requires a data-backed understanding of the current systems and logical next steps, ensuring business runs as usual. There are many challenges that an enterprise may face throughout its cloud journey. Most of these may come as surprise as teams often are unaware of the chronological order in which the complexities occur.
Relevance Lab, an AWS partner, has an integrated approach and offerings developed through years of experience in delivering successful cloud journeys to clients across all industries and regions. Like the global publishing major discussed in the blog, we have helped clients significantly reduce costs by implementing modernizations backstage parallelly while their businesses run as usual.
To know more about cloud migration or implement the same for your enterprise, feel free to connect with marketing@relevancelab.com
References:
Cloud Management, Automation, DevOps and AIOps – Key Offerings from Relevance Lab
Relevance Lab Playbooks for Frictionless IT and Business Operations
Leveraging Technology + Consulting Specialization for Products and Solutions